お疲れ様です!IT業界で働くアライグマです!
「今週末はデータベースのバージョンアップ作業か……」
カレンダーの予定を見るたびに、胃がキリキリと痛むような感覚。エンジニアなら誰しも一度は経験があるのではないでしょうか。アプリケーションのデプロイなら万が一バグがあってもすぐに修正版を当てれば済みますが、データベースとなると話は別です。
「データが消えたらどうしよう」
「メンテナンス時間内に終わらなかったら?」
「バージョンアップ後に原因不明のパフォーマンス劣化が起きたら……」
取り返しのつかない事態への想像が、恐怖を増幅させます。私もインフラエンジニアとしてキャリアをスタートさせた頃、MySQLのメジャーバージョンアップ作業の前夜は一睡もできませんでした。特に、間違って本番環境で DROP TABLE を実行してしまう悪夢は、何度も見ました。
しかし、数々の修羅場と成功体験を経て、私は一つの結論に達しました。「恐怖」の正体は「準備不足」と「未知」であると。
この記事では、かつて手が震えるほどDBメンテナンスを恐れていた私が、PjM(プロジェクトマネージャー)の視点も交えながら、その恐怖を「自信」に変えるための具体的なステップを共有します。精神論ではなく、リスクを物理的に減らすための技術とプロセスです。
なぜデータベースのバージョンアップはこれほどまでに「怖い」のか
まず、敵を知ることから始めましょう。なぜ私たちはこれほどまでにデータベースの操作を恐れるのでしょうか。
データのロストという不可逆なリスク
最大の理由は、やはり「データの損失(ロスト)」です。アプリケーションコードはGitで管理されており、いつでも前のバージョンに戻せます(ステートレス)。しかし、データベースの状態(ステート)は生き物です。バックアップがあるとはいえ、リストアには時間がかかりますし、バックアップ取得以降のデータはどうしても失われる可能性があります。この「やり直しがきかない」というプレッシャーは計り知れません。
データベースの基本的な種類や特徴について復習したい方は、【2025年版】データベースの種類を総まとめ!RDBMSとNoSQLの違いから最適な選び方まで徹底解説も参考にしてみてください。
ブラックボックス化しやすい挙動変化
DBエンジンのバージョンアップには、オプティマイザの変更が含まれることがよくあります。これによって、昨日まで高速に動いていたクエリが、バージョンアップ当日から突然フルスキャンを始めてシステムを停止に追い込む、といった「サイレントキラー」な事象が発生しがちです。テスト環境ではデータ量が少なくて気づかないことも多く、本番で初めて牙を剥くのです。
私が体験した「心停止」の瞬間
今でも鮮明に覚えている失敗があります。あるWebサービスのPostgreSQLバージョンアップ作業中、手順書通りに新サーバーへ切り替えた瞬間、アプリケーションから大量のコネクションエラーが吐き出されました。原因は、pg_hba.conf(接続認証設定)の記述ミスでした。単純なミスですが、サービス停止のアラートが鳴り響く中、真っ白になった頭でviエディタを操作するあの数分間は、人生で最も長い時間でした。
この経験から学んだのは、「人間の記憶や注意力を信用してはいけない」ということです。
最新のデータベーストレンドや他社の事例を学ぶには、こちらの雑誌 Software Design (ソフトウェアデザイン) 2025年10月号 [雑誌] が定期的に役立ちます。定期購読しておくと、自然と情報が入ってくるのでおすすめです。

「恐怖」の正体を分解する:リスクを可視化する技術
漠然とした不安は恐怖を生みますが、特定されたリスクは「課題」に変わります。課題になれば、解決策を用意できます。
影響範囲の特定(アプリケーション、バッチ、連携システム)
まず行うべきは、そのデータベースを利用しているクライアントの全貌把握です。
Webアプリケーションサーバーだけではありません。
- 夜間バッチサーバー
- BIツールや分析基盤
- 管理画面
- 開発者がローカルから接続している踏み台サーバー
これら全てを洗い出し、それぞれの接続設定や依存ライブラリ(ドライバのバージョンなど)を確認します。「知らなかった接続元」が当日エラーを吐くのが一番の恐怖です。
システム全体の健全性を保つためには、日頃からのログ監視も重要です。ログ監視のベストプラクティス!障害の予兆を検知して平穏な夜を取り戻す方法では、異常検知の仕組みづくりについて解説しています。
非互換項目の徹底的な洗い出し
各DBベンダーは、バージョンアップ時の「非互換変更点(Breaking Changes)」をドキュメントとして公開しています。これを一言一句漏らさずに読み込むことが、エンジニアとしての誠実さです。
- 廃止されるデータ型や関数を使っていないか?
- 予約語に追加された単語をテーブル名やカラム名に使っていないか?(例:MySQL 8.0での
RANK関数など) - デフォルトの設定値が変わるパラメータはないか?
これらを静的解析ツールやgrepでコードベース全体から調査します。ここで手を抜くと、後で必ずしっぺ返しを食らいます。例えば、MySQL 5.7から8.0への移行では、GROUP BY句の挙動変更により、多くのクエリが修正を余儀なくされました。こうした情報を事前にキャッチアップしておくことが、リスク低減の鍵となります。
プロジェクト管理においては、こうした「見えないリスク」を指標化することも大切です。この本 Measure What Matters(OKR) は、目標設定と進捗管理の考え方を根本から変えてくれます。

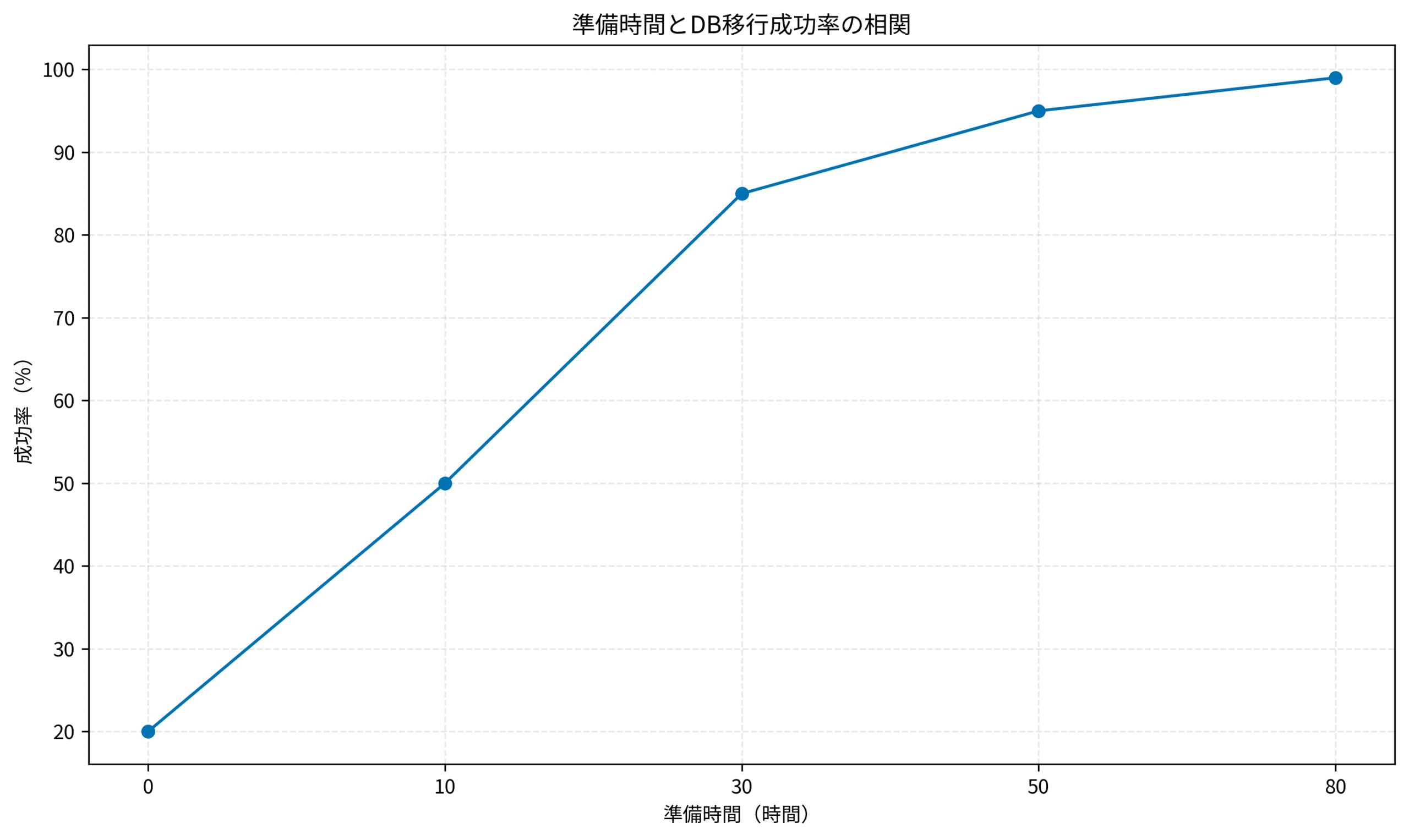
転ばぬ先の杖:鉄壁の検証環境とリハーサル
準備の8割はここで決まります。本番作業がスムーズにいくかどうかは、事前の検証にかかっています。
本番相当データでの検証が絶対条件
開発環境のスカスカなデータで「動作確認OK」とするのは自殺行為です。必ず本番環境からマスク(秘匿化)したデータを検証環境にインポートし、本番と同等のデータ量で検証を行ってください。個人情報が含まれる場合は、適切なマスキングツールを使用して、セキュリティリスクを排除した上で検証環境へコピーします。
特に重要なのが「所要時間の計測」です。
データの移行やインデックスの再構築にどれくらい時間がかかるのか。これはデータ量に比例して増大します。「1時間で終わると思っていたら10時間かかった」という事態を防ぐため、本番データ量でのリハーサルは必須です。
本番DBへのフルアクセス権限、本当に必要?リスクと適切な権限管理の考え方でも触れましたが、本番環境での操作は常にリスクと隣り合わせです。権限管理を徹底し、誤操作を防ぐ仕組みもリハーサルの一環として確認しましょう。
切り戻し手順(バックアッププラン)こそが命綱
「成功させる手順」よりも重要なのが、「失敗したときに元に戻す手順」です。これを切り戻し(ロールバック)手順と呼びます。
- どのタイミングまでなら引き返せるか(Point of No Return)
- 切り戻しにかかる時間はどれくらいか
- 切り戻し判断を行う基準(例:作業予定時間を〇分超過したら無条件で切り戻す)
この命綱があるからこそ、私たちは暗闇の中でも綱渡りができるのです。手順書には、必ず「正常系」の隣に「異常系(切り戻し)」の手順を併記しましょう。
データベース設計や運用の基礎を固めるには、この一冊 インフラエンジニアの教科書 がバイブルとしておすすめです。設計段階からバージョンアップを見越した構成にしておくことが、将来の自分を助けます。正規化の理論から物理設計まで、網羅的に学べます。
当日の心構えとチーム体制:一人で背負わないこと
技術的な準備が整ったら、あとは当日の運用体制です。ここで大切なのは「一人でやらない」ことです。
作業分担とダブルチェックの徹底
どんなに優秀なエンジニアでも、プレッシャーのかかる状況ではミスをします。コマンドの入力ミス、確認漏れ……。これらを防ぐには、以下の役割分担が有効です。
- オペレーター(操作者): 実際にコマンドを入力する人
- ナビゲーター(確認者): 手順書を読み上げ、オペレーターの画面を見て確認する人
- コマンダー(判断者): 全体の進捗を管理し、Go/No-Goの判断を下す人(PjMなどが担当)
オペレーターが孤独に作業するのではなく、チームとして作業にあたることで、心理的な負担は劇的に軽くなります。「誰かが見ていてくれる」という安心感は、ミスを減らす最大の特効薬です。
判断ポイント(Go/No-Go)の明確化
作業中は「想定外」のことばかり起きます。「ちょっとエラーが出たけど、無視して進めて大丈夫かな……」という迷いが、最大の事故の元です。
事前に「このエラーが出たら即中止」「この時間までにここが終わらなければ切り戻し」という撤退基準を明確にしておきましょう。迷う時間をなくすことが、冷静さを保つ秘訣です。
システム運用におけるトラブルシューティングの基礎については、「バグ」と「エラー」の違い、説明できますか?エンジニアのストレスを減らすための基礎知識もあわせてご覧ください。
障害対応やチーム運営については、3カ月で改善!システム障害対応 実践ガイド が非常に実践的です。

バージョンアップを乗り越えた先にあるもの
これだけの準備をして臨むバージョンアップ作業。当日は緊張するでしょうが、それは「良い緊張感」です。
パフォーマンス向上と新機能の恩恵
無事にバージョンアップが完了すれば、最新の機能やパフォーマンス改善の恩恵を受けられます。クエリが速くなり、新機能を使って開発効率が上がる。それは、システムを利用するユーザーにとっても、開発するエンジニアにとっても大きな価値です。
PostgreSQLクエリチューニング:EXPLAIN ANALYZEで実行計画を最適化する実践テクニックでは、バージョンアップ後のパフォーマンス劣化を防ぐためのチューニング手法を詳しく解説しています。チーム開発やカルチャーづくりの視点では、Team Geek ―Googleのギークたちはいかにしてチームを作るのか から得られる示唆も多いでしょう。
エンジニアとしての自信と信頼
何より、困難なミッションを計画通りに完遂した経験は、エンジニアとしての大きな自信になります。「あのDB移行を乗り越えたんだから」という事実は、その後のキャリアにおいても強力な支えとなるでしょう。また、安定稼働を守り抜いたことで、チームや経営陣からの信頼も厚くなるはずです。
特に、PostgreSQLのメジャーバージョンアップで pg_upgrade コマンドを使う際、リンクモード(--link)での高速化は魅力ですが、失敗時のリカバリ手順が複雑になる点は要注意です。私は過去のプロジェクトで、このリスクを避けるために、あえてダンプ&リストア方式を選択し、ダウンタイムを許容する代わりに確実性を取ったこともあります。こうした「技術的なトレードオフ」を経営陣に説明し、納得してもらうのもPjMの重要な役割です。
インフラエンジニアとしての基礎体力をつけるなら、先ほど紹介した一冊を通じてネットワークからサーバ構築まで、インフラ全般の知識を体系的に身につけておくと安心です。

まとめ
データベースのバージョンアップに対する恐怖は、決して恥ずかしいことではありません。それはシステムの重要性を理解している証拠です。しかし、その恐怖に立ちすくんでいては前に進めません。
- リスクを具体的に可視化する(影響範囲・非互換)
- 本番相当のデータで徹底的にリハーサルする
- 切り戻し手順(命綱)を用意する
- チーム体制で心理的安全性を確保する
これらを実践することで、恐怖は「制御可能なリスク」に変わります。
さあ、深呼吸して、準備を始めましょう。万全の準備があれば、当日のコーヒーはきっと美味しく感じられるはずです。








