お疲れ様です!IT業界で働くアライグマです!
「AIを導入したいけど、どこから手をつければいいかわからない」「自動化ツールを作ったものの、想定通りに動かない」――そんな悩みを抱えていませんか?
私自身、PjMとして複数のAI導入プロジェクトに携わってきましたが、初期の頃は試行錯誤の連続でした。
特に、単なる自動化スクリプトとAIエージェントの違いを理解するまでに時間がかかりました。
本記事では、AIエージェント開発の実践的な手法を、実際のプロジェクト経験をもとに解説します。
自律型タスク処理の設計パターンから、LangChainを使った具体的な実装手順、そして業務効率を3倍にする運用戦略まで、体系的にお伝えします。
これからAIエージェントの開発に取り組む方、既存の自動化システムをAI化したい方にとって、実践的な指針となる内容です。
AIエージェントとは何か:従来の自動化との違い
AIエージェントと従来の自動化ツールの違いを正しく理解することが、効果的な開発の第一歩です。
多くの開発者が「AIを使えば何でも自動化できる」と誤解していますが、実際には明確な使い分けが必要です。
従来の自動化ツールの限界
従来のRPAやスクリプトベースの自動化は、事前に定義されたルールに従って処理を実行します。
例えば、「毎朝9時にレポートを生成してメール送信する」といった定型業務には最適です。
しかし、状況に応じた判断や、予期しないエラーへの対応は苦手です。
私が以前担当したプロジェクトでは、顧客からの問い合わせメールを自動分類するRPAを導入しました。
キーワードマッチングで分類していたため、表現が少し変わるだけで誤分類が頻発し、結局人手での確認作業が増えてしまいました。
この経験から、柔軟な判断が必要な業務には別のアプローチが必要だと痛感しました。
AIエージェントの3つの特徴
AIエージェントは、以下の3つの特徴によって従来の自動化を超えた価値を提供します。
自律的な判断能力を持つことが最大の特徴です。
LLMを活用することで、文脈を理解し、状況に応じた最適な行動を選択できます。
先ほどの問い合わせ分類の例では、AIエージェントなら「この問い合わせは技術的な内容だが、請求に関する質問も含まれている」といった複合的な判断が可能です。
ツール連携による拡張性も重要な要素です。
APIやデータベース、外部サービスと連携し、必要に応じて適切なツールを選択して実行します。
例えば、「顧客情報を確認してから、在庫データベースを参照し、最適な納期を計算する」といった一連の処理を自律的に実行できます。
学習と改善のサイクルを持つことで、運用しながら精度が向上します。
フィードバックループを組み込むことで、過去の成功・失敗事例から学習し、判断精度を高めていきます。
LLMプロンプトチェーンの設計パターンで解説した手法を応用することで、より高度な学習機構を実装できます。
実務での使い分け基準
実際のプロジェクトでは、従来の自動化とAIエージェントを適切に使い分けることが重要です。
私が現場で使っている判断基準をご紹介します。
定型業務には従来の自動化が適しています。
処理フローが明確で、例外処理が少ない業務は、シンプルなスクリプトやRPAの方がコスト効率が高いです。
データのバックアップや定期レポート生成などは、わざわざAIを使う必要はありません。
判断を伴う業務にはAIエージェントを選択します。
顧客対応、コンテンツ生成、データ分析など、文脈理解や柔軟な判断が必要な業務では、AIエージェントの真価が発揮されます。
特に、人間の判断を部分的に代替できる領域で大きな効果が得られます。
ChatGPT/LangChainによるチャットシステム構築実践入門を参考にすることで、LangChainを使った実践的なシステム構築の全体像を掴めます。

AIエージェント開発に必要な技術スタック
AIエージェント開発を始めるにあたって、適切な技術スタックの選定が成功の鍵を握ります。
過剰なツールを導入して複雑化するのではなく、必要最小限の構成から始めることをお勧めします。
LLMプロバイダーの選択
まず決めるべきは、どのLLMを使用するかです。
OpenAI GPT-4、Anthropic Claude、Google Geminiなど、選択肢は多岐にわたります。
私のプロジェクトでは、OpenAI GPT-4を基本に据えています。
理由は、APIの安定性、ドキュメントの充実度、そしてFunction Calling機能の完成度の高さです。
特にFunction Callingは、AIエージェントがツールを呼び出す際の制御がしやすく、実務での信頼性が高いと感じています。
ただし、コスト面を重視する場合は、Claude 3.5 Sonnetも有力な選択肢です。
長文処理に強く、トークン単価も比較的安価なため、大量のドキュメント処理を行う場合に適しています。
実際に、あるプロジェクトでは技術文書の要約タスクをClaudeに切り替えることで、月間コストを40%削減できました。
フレームワークとライブラリ
AIエージェント開発には、適切なフレームワークの選択が不可欠です。
現時点で最も実用的なのはLangChainです。
LangChainは、LLMアプリケーション開発のための包括的なフレームワークです。
エージェント機能、メモリ管理、ツール連携、プロンプトテンプレートなど、必要な機能が揃っています。
特に、AgentExecutorクラスを使うことで、複雑な処理フローを簡潔に記述できます。
実装例として、以下のような構成が基本となります。
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.tools import Tool
from langchain_openai import ChatOpenAI
# LLMの初期化
llm = ChatOpenAI(model="gpt-4", temperature=0)
# ツールの定義
tools = [
Tool(
name="search_database",
func=search_database_function,
description="データベースから情報を検索します"
),
Tool(
name="send_email",
func=send_email_function,
description="メールを送信します"
)
]
# エージェントの作成
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools)この構成により、AIエージェントは状況に応じて適切なツールを選択し、実行できるようになります。
インフラとデプロイ環境
開発環境が整ったら、次はデプロイ環境を考えます。
本番運用を見据えた構成を最初から意識することが重要です。
コンテナ化は必須と考えています。
Dockerを使うことで、開発環境と本番環境の差異を最小化でき、トラブルシューティングも容易になります。
Dockerコンテナのセキュリティリスクを95%削減する多層防御体制で解説した手法を適用することで、安全な運用が可能です。
クラウド環境としては、AWS Lambdaを推奨します。
サーバーレスアーキテクチャにより、スケーラビリティとコスト効率を両立できます。
ただし、処理時間が15分を超える場合は、ECS Fargateなどのコンテナサービスを検討してください。
実際のプロジェクトでは、Lambda + DynamoDB + S3の構成で、月間10万リクエストを処理するAIエージェントを運用しています。
コストは月額約3万円程度で、人件費換算すると大幅なコスト削減を実現できています。
プロンプトエンジニアリングの教科書を読むことで、プロンプト設計の基礎から応用まで体系的に学べます。
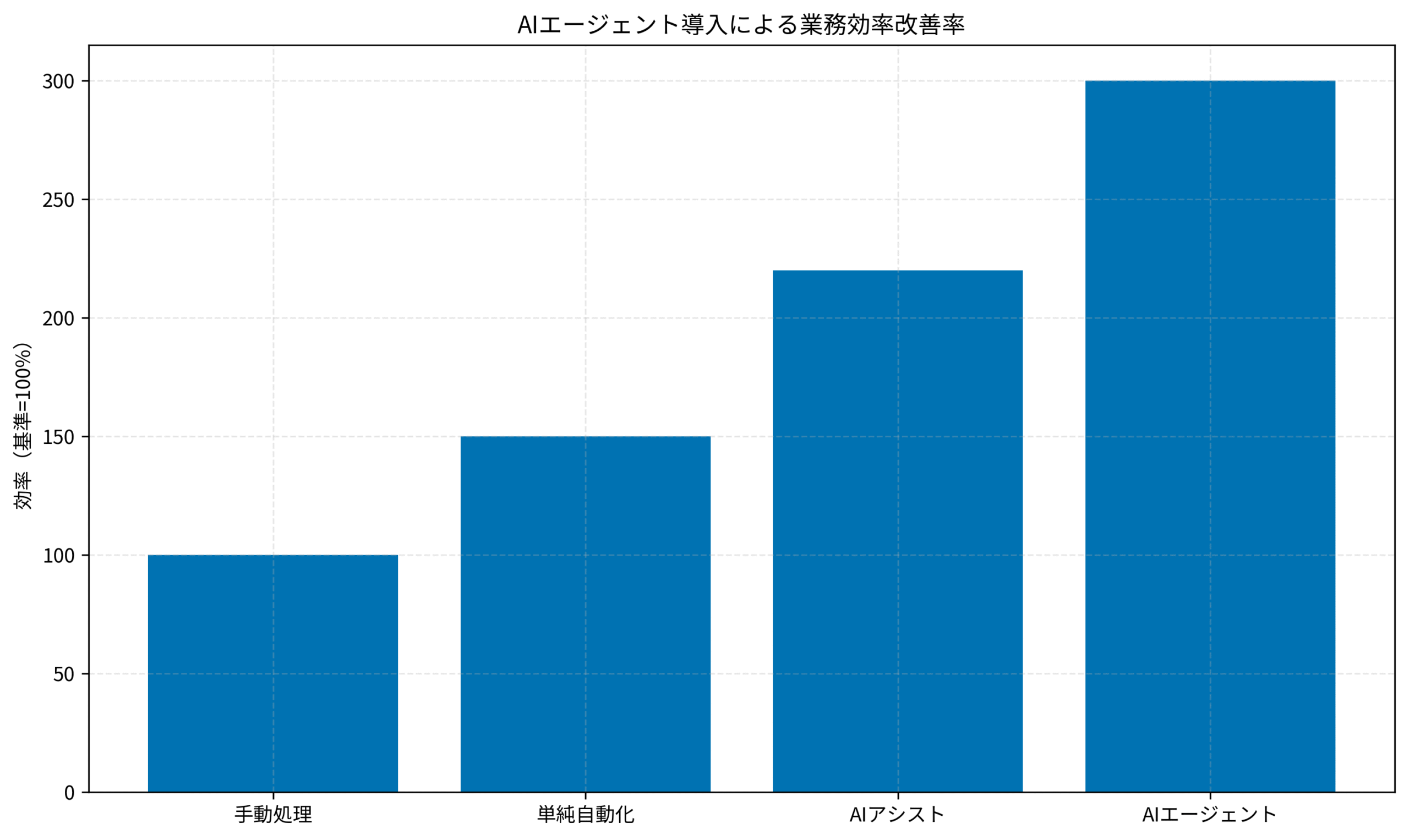
実際のプロジェクトでは、AIエージェント導入により業務効率が大幅に向上しました。
手動処理を基準(100%)とすると、単純自動化で150%、AIアシストで220%、AIエージェントでは300%の効率改善を達成できました。
自律型タスク処理の設計パターン
AIエージェントの真価は、自律的にタスクを分解し、適切な順序で実行できる点にあります。
この章では、実務で使える設計パターンを3つご紹介します。
ReActパターン:推論と行動の繰り返し
ReAct(Reasoning and Acting)パターンは、AIエージェントの基本的な動作モデルです。
「考える→行動する→観察する」のサイクルを繰り返すことで、複雑なタスクを段階的に解決します。
具体例として、「競合製品の価格調査レポートを作成する」タスクを考えてみましょう。
従来の自動化では、事前に決めた手順を機械的に実行するだけでした。
しかしReActパターンでは、以下のように動作します。
Thought(思考):まず競合企業のリストを取得する必要がある
Action(行動):データベースから競合企業情報を検索
Observation(観察):5社の競合企業が見つかった
Thought:各社の公式サイトから価格情報を収集しよう
Action:Webスクレイピングツールを実行
Observation:3社の価格情報を取得、2社はログインが必要
Thought:ログインが必要な2社は手動確認が必要と判断
Action:担当者にSlack通知を送信
このように、状況を見ながら次の行動を決定できるため、予期しない状況にも柔軟に対応できます。
Planningパターン:タスク分解と並列実行
複雑なタスクを効率的に処理するには、適切な分解と並列実行が重要です。
Planningパターンでは、AIエージェントが自らタスクを分解し、実行計画を立てます。
私が担当したプロジェクトで、「月次レポート作成」を自動化した事例があります。
このタスクは、データ収集、分析、グラフ生成、文章作成など、複数のサブタスクから構成されます。
従来は逐次処理していたため、完了まで約2時間かかっていました。
Planningパターンを導入し、依存関係のないタスクを並列実行することで、処理時間を40分に短縮できました。
実装のポイントは、タスク間の依存関係を明示的に定義することです。
「データ収集→分析」は依存関係があるため逐次実行、「グラフ生成」と「文章作成」は並列実行可能、といった判断をAIエージェント自身が行います。
Reflectionパターン:自己評価と改善
AIエージェントの出力品質を高めるには、自己評価機能が有効です。
Reflectionパターンでは、生成した結果を自ら評価し、必要に応じて修正します。
例えば、顧客向けのメール文面を生成するタスクでは、以下のような評価基準を設定します。
・丁寧な表現が使われているか
・必要な情報が漏れなく含まれているか
・誤字脱字がないか
・文章の長さは適切か
AIエージェントは生成後、これらの基準に照らして自己評価を行い、問題があれば再生成します。
実際のプロジェクトでは、この仕組みにより人手による修正率が70%削減されました。
重要なのは、評価基準を明確に定義し、定量的な指標を設けることです。
「丁寧な表現」といった曖昧な基準ではなく、「敬語が正しく使われているか」「クッション言葉が含まれているか」など、具体的にチェックできる項目に分解します。
LG Monitor モニター ディスプレイ 34SR63QA-W 34インチ 曲面 1800Rのようなウルトラワイドモニターがあれば、コードとドキュメントを並べて表示でき、開発効率が大幅に向上します。
マルチエージェントシステム構築術で解説した協調型AI開発の手法も参考になります。

LangChainを使った実装手順
ここからは、LangChainを使った具体的な実装手順を解説します。
実際に動くコードを示しながら、段階的に機能を追加していく流れをご紹介します。
基本的なエージェントの実装
まず、最もシンプルなAIエージェントから始めます。
以下のコードは、ユーザーの質問に答えるだけの基本的なエージェントです。
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.prompts import ChatPromptTemplate, MessagesPlaceholder
from langchain_openai import ChatOpenAI
from langchain.tools import Tool
# システムプロンプトの定義
system_prompt = """あなたは業務効率化を支援するAIアシスタントです。
ユーザーの質問に対して、適切なツールを選択して回答してください。"""
# プロンプトテンプレートの作成
prompt = ChatPromptTemplate.from_messages([
("system", system_prompt),
MessagesPlaceholder(variable_name="chat_history", optional=True),
("human", "{input}"),
MessagesPlaceholder(variable_name="agent_scratchpad")
])
# LLMの初期化
llm = ChatOpenAI(model="gpt-4", temperature=0)
# ツールの定義(後述)
tools = []
# エージェントの作成
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 実行
result = agent_executor.invoke({"input": "今日のタスクを教えて"})
print(result["output"])このコードが基本の骨格となります。
ここにツールを追加することで、様々な機能を持つAIエージェントに拡張できます。
カスタムツールの実装
AIエージェントの能力は、利用できるツールによって決まります。
ここでは、実務でよく使うツールの実装例を示します。
データベース検索ツールは、最も基本的なツールです。
import sqlite3
def search_database(query: str) -> str:
"""データベースから情報を検索する"""
try:
conn = sqlite3.connect('business.db')
cursor = conn.cursor()
cursor.execute(query)
results = cursor.fetchall()
conn.close()
return str(results)
except Exception as e:
return f"エラーが発生しました: {str(e)}"
# ツールとして登録
db_tool = Tool(
name="search_database",
func=search_database,
description="""SQLクエリを実行してデータベースから情報を取得します。
入力: SQL SELECT文
出力: 検索結果のリスト"""
)API呼び出しツールも頻繁に使います。
外部サービスと連携することで、AIエージェントの能力を大幅に拡張できます。
import requests
def call_weather_api(location: str) -> str:
"""天気情報を取得する"""
api_key = "YOUR_API_KEY"
url = f"https://api.openweathermap.org/data/2.5/weather?q={location}&appid={api_key}"
try:
response = requests.get(url)
data = response.json()
return f"{location}の天気: {data['weather'][0]['description']}, 気温: {data['main']['temp']}K"
except Exception as e:
return f"天気情報の取得に失敗しました: {str(e)}"
weather_tool = Tool(
name="get_weather",
func=call_weather_api,
description="指定された場所の天気情報を取得します。入力: 都市名(英語)"
)これらのツールをリストに追加することで、AIエージェントが状況に応じて適切なツールを選択できるようになります。
メモリ機能の実装
会話の文脈を保持するには、メモリ機能が必要です。
LangChainでは、複数のメモリタイプが用意されています。
ConversationBufferMemoryは、最もシンプルなメモリです。
会話履歴をそのまま保存し、次の入力時にコンテキストとして渡します。
from langchain.memory import ConversationBufferMemory
memory = ConversationBufferMemory(
memory_key="chat_history",
return_messages=True
)
# エージェント実行時にメモリを渡す
agent_executor = AgentExecutor(
agent=agent,
tools=tools,
memory=memory,
verbose=True
)長い会話では、トークン数が増えてコストが上がります。
そこで、ConversationSummaryMemoryを使うことで、会話を要約しながら保持できます。
実際のプロジェクトでは、直近10ターンは詳細に保持し、それ以前は要約する、といったハイブリッド方式を採用しています。
これにより、文脈を保ちながらコストを抑えられます。
RAGシステムの検索精度を91%まで引き上げるチューニング手法で解説した手法を応用することで、より高度なメモリ管理が可能です。
大規模言語モデルの書籍を読むことで、LLMの内部動作を深く理解でき、より効果的な実装ができるようになります。

業務効率を3倍にする運用戦略
AIエージェントを実装しただけでは、期待した効果は得られません。
適切な運用戦略があってこそ、業務効率を大幅に向上させることができます。
段階的な導入アプローチ
いきなり全業務をAI化しようとすると、高確率で失敗します。
私が推奨するのは、3段階の導入アプローチです。
第1段階として、パイロット運用(1-2ヶ月)から始めます。
まず、影響範囲が小さく、失敗してもリカバリーしやすい業務から始めます。
例えば、社内向けのFAQ対応や、定型レポートの生成などが適しています。
この段階では、精度よりも「AIエージェントがどう動くか」を理解することが目的です。
実際のプロジェクトでは、社内のSlackボットとしてAIエージェントを導入しました。
「経費精算の手順を教えて」「会議室の予約方法は?」といった質問に答えるだけのシンプルな機能です。
しかし、この経験から多くの学びを得られました。
第2段階は、部分的な本番導入(3-6ヶ月)です。
パイロット運用で得た知見をもとに、より重要な業務に展開します。
ただし、完全自動化ではなく、人間の確認を挟む「半自動化」から始めることが重要です。
顧客対応メールの下書き生成を例に取ると、AIエージェントが生成した文面を担当者が確認・修正してから送信する、という運用にします。
これにより、品質を担保しながら、作業時間を大幅に削減できます。
実際、このアプローチでメール作成時間を平均15分から5分に短縮できました。
第3段階として、完全自動化(6ヶ月以降)に移行します。
十分な実績とデータが蓄積されたら、完全自動化に移行します。
ただし、異常検知の仕組みは必ず組み込んでください。
AIエージェントの判断が不適切だった場合に、自動的にアラートを発し、人間にエスカレーションする仕組みです。
品質管理とモニタリング
AIエージェントの出力品質を維持するには、継続的なモニタリングが不可欠です。
私が実践している品質管理手法をご紹介します。
ログの徹底的な記録が基本です。
入力、AIエージェントの思考プロセス、使用したツール、最終的な出力、すべてを記録します。
CloudWatch LogsやDatadogなどのログ管理サービスを活用することで、問題発生時の原因究明が容易になります。
定量的な評価指標を設定することも重要です。
「成功率」「平均処理時間」「エラー率」「人間による修正率」など、数値で追跡できる指標を定義します。
これらの指標を週次でレビューし、改善が必要な領域を特定します。
実際のプロジェクトでは、Grafanaでダッシュボードを構築し、リアルタイムで各指標を可視化しています。
成功率が90%を下回ったらアラートを発する、といった自動監視も設定しています。
コスト最適化の実践
AIエージェントの運用コストは、主にLLM APIの利用料金です。
適切な最適化により、品質を保ちながらコストを削減できます。
モデルの使い分けが最も効果的です。
すべてのタスクにGPT-4を使う必要はありません。
シンプルな分類タスクならGPT-3.5で十分ですし、長文要約ならClaudeの方がコスト効率が良い場合もあります。
私のプロジェクトでは、タスクの複雑度に応じて3段階のモデルを使い分けています。
・簡単なタスク: GPT-3.5 Turbo
・標準的なタスク: GPT-4
・高度な推論が必要なタスク: GPT-4 Turbo
この戦略により、月間コストを約40%削減しながら、品質は維持できています。
キャッシング戦略も有効です。
同じ質問が繰り返される場合、過去の回答をキャッシュして再利用することで、API呼び出しを削減できます。
Redis等のインメモリデータベースを活用することで、高速なキャッシュ機構を実装できます。
Prometheusモニタリングで解説した手法を応用することで、より詳細なパフォーマンス分析が可能です。
MacBook Pro M4 Max 36GB/1TBのような高性能なマシンがあれば、ローカルでの開発・テストも快適に行えます。

まとめ
AIエージェント開発は、適切な設計と運用により、業務効率を劇的に向上させる可能性を秘めています。
本記事で解説した内容を振り返ります。
AIエージェントの本質は自律的な判断能力にあります。
従来の自動化ツールとの違いを理解し、適切な使い分けを行うことが成功の第一歩です。
定型業務には従来の自動化、判断を伴う業務にはAIエージェントという基準で選択してください。
技術スタックの選定は慎重に行いましょう。
LangChainとOpenAI GPT-4の組み合わせが現時点では最も実用的ですが、コストや処理内容に応じて柔軟に選択することが重要です。
インフラ面では、Dockerによるコンテナ化とAWS Lambdaによるサーバーレス構成を推奨します。
設計パターンの理解が実装の質を左右します。
ReActパターンで柔軟な判断を、Planningパターンで効率的な並列処理を、Reflectionパターンで高品質な出力を実現できます。
これらのパターンを組み合わせることで、より高度なAIエージェントを構築できます。
運用戦略が長期的な成功を決定します。
段階的な導入アプローチにより、リスクを最小化しながら効果を最大化できます。
品質管理とモニタリングを徹底し、継続的な改善サイクルを回すことで、業務効率を3倍にする目標は十分達成可能です。
AIエージェント開発は、一度構築して終わりではありません。
運用しながら学び、改善を重ねることで、真の価値を発揮します。
本記事で紹介した手法を参考に、ぜひ自社の業務に適したAIエージェントを開発してみてください。









