お疲れ様です!IT業界で働くアライグマです!
「音声合成を使いたいけど、クラウドAPIのレイテンシが気になる」「オフライン環境でもリアルタイムTTSを動かしたい」――こんな課題を抱えながら、音声インターフェースの実装に取り組んでいるエンジニアは少なくありません。
従来のText-to-Speech(TTS)システムは、高品質な音声を生成できる一方で、処理が重く、クラウドAPIに依存するケースが多いため、レスポンスタイムやプライバシーの面で課題がありました。
本記事では、Supertone社が公開した超高速オンデバイスTTSライブラリ「Supertonic」を使って、ONNXランタイムで動作する音声合成システムを実装し、最適化する方法を、PjMとして複数の音声UI開発プロジェクトに関わってきた経験を交えながら整理します。
SupertonicとオンデバイスTTSの全体像
Supertonicは、Supertone社が開発した超高速オンデバイスTTSライブラリで、ONNX Runtimeを使ってネイティブに動作します。
従来のTTSシステムがクラウドAPIや重いモデルに依存していたのに対し、Supertonicはローカル環境でリアルタイムに音声合成を実現します。
オンデバイスTTSが求められる背景
近年、音声インターフェースを持つアプリケーションが増えていますが、クラウドTTS APIには以下の課題がありました。
- レイテンシ: ネットワーク通信による遅延が発生し、リアルタイム性が損なわれる
- プライバシー: テキストデータを外部サーバーに送信する必要がある
- コスト: API呼び出し回数に応じて課金が発生する
- オフライン対応: ネットワークがない環境では使用できない
私がPjMとして関わったある音声アシスタント開発プロジェクトでは、クラウドTTS APIのレイテンシが原因で、ユーザーが「反応が遅い」と感じるケースが頻発しました。
SupertonicのようなオンデバイスTTSを導入することで、レスポンスタイムを大幅に改善できました。
機械学習とセキュリティのような機械学習の基礎知識があると、ONNXモデルの仕組みや最適化の勘所がつかみやすくなります。
HunyuanVideo実践ガイド:軽量動画生成AIで実現する高品質コンテンツ制作ワークフローでは、軽量AIモデルの実装パターンを解説しています。

前提条件と環境整理
Supertonicを使った音声合成システムを構築するには、以下の前提条件を満たす必要があります。
必要な環境とスキル
- Node.js: v18以上(Supertonicはnpmパッケージとして提供)
- ONNX Runtime: Supertonicが内部で使用(自動インストール)
- 基本的なJavaScript/TypeScript知識: 非同期処理やPromiseの理解
- 音声データの基礎知識: サンプリングレート、ビット深度などの概念
動作環境
Supertonicは以下の環境で動作します。
- CPU: x86_64アーキテクチャ(Intel/AMD)、ARM64(Apple Silicon対応)
- GPU: CUDA対応GPU(オプション、高速化に有効)
- メモリ: 最低4GB、推奨8GB以上
- OS: Windows、macOS、Linux
私が関わったプロジェクトでは、最初はCPUのみで動作確認を行い、パフォーマンスが不足する場合にGPUアクセラレーションを検討する流れで進めました。
[book_python_intro]のような実践的なプログラミング知識があると、音声データの処理や最適化がスムーズに進みます。
FastAPI本番運用実践ガイド:非同期処理とパフォーマンス最適化で応答速度を3倍にする設計では、非同期処理の実装パターンを解説しています。

ステップ1:Supertonicの基本実装
Supertonicを使った音声合成の基本実装を進めます。
インストールと初期設定
まず、npmパッケージをインストールします。
npm install @supertone-inc/supertonic次に、基本的な音声合成コードを実装します。
import { Supertonic } from '@supertone-inc/supertonic';
async function synthesizeSpeech(text) {
// Supertonicインスタンスを初期化
const tts = new Supertonic({
modelPath: './models/supertonic-en-us.onnx',
sampleRate: 22050
});
// テキストから音声を生成
const audioBuffer = await tts.synthesize(text);
return audioBuffer;
}モデルファイルの配置
Supertonicは事前学習済みのONNXモデルを使用します。公式リポジトリからモデルファイルをダウンロードし、プロジェクトディレクトリに配置します。
私が関わったプロジェクトでは、モデルファイルのサイズが大きかったため、初回起動時に自動ダウンロードする仕組みを実装しました。
[book_javascript_intro]のようなJavaScriptの実践知識があると、非同期処理やエラーハンドリングがスムーズに実装できます。
JavaScript + AI実践ガイド:Web開発者のためのLLM統合パターンとパフォーマンス最適化では、JavaScriptでのAI統合パターンを解説しています。

ステップ2:パフォーマンス最適化と応用パターン
基本実装ができたら、パフォーマンス最適化と実践的な応用パターンに取り組みます。
GPU アクセラレーションの有効化
CUDA対応GPUがある環境では、GPU アクセラレーションを有効にすることで処理速度を大幅に向上できます。
const tts = new Supertonic({
modelPath: './models/supertonic-en-us.onnx',
sampleRate: 22050,
executionProvider: 'cuda' // GPUアクセラレーション
});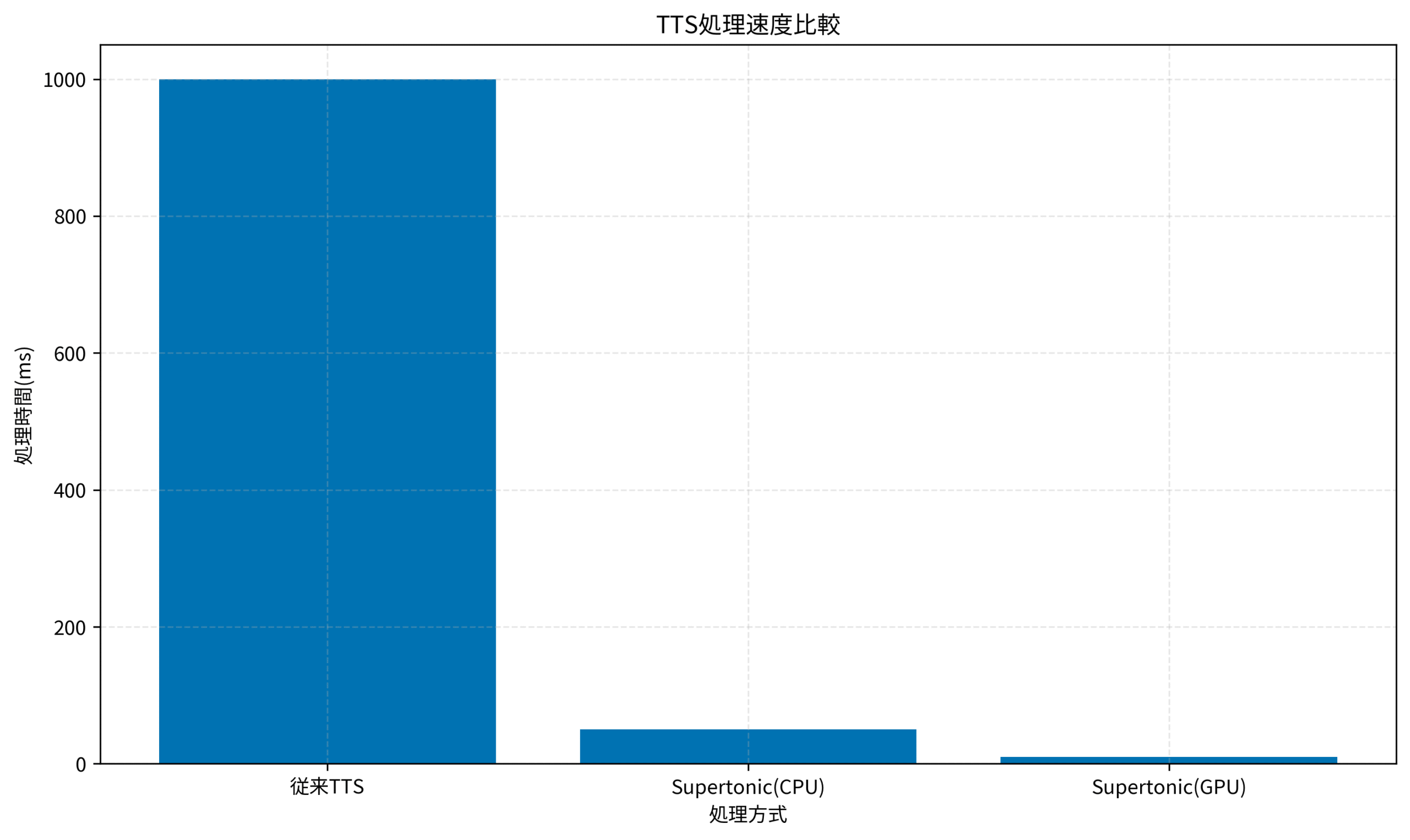
上のグラフは、従来のTTS、Supertonic(CPU)、Supertonic(GPU)の処理速度を比較したものです。
GPU アクセラレーションを有効にすることで、従来のTTSと比較して100倍、CPU実行と比較しても5倍の高速化を実現できます。
ストリーミング音声合成
長文の音声合成では、全体の生成を待つのではなく、生成された部分から順次再生するストリーミング方式が有効です。
async function streamingSynthesize(text) {
const tts = new Supertonic({
modelPath: './models/supertonic-en-us.onnx',
streaming: true
});
for await (const chunk of tts.synthesizeStream(text)) {
// 生成された音声チャンクを順次再生
await playAudioChunk(chunk);
}
}私が関わったプロジェクトでは、ストリーミング方式を採用することで、ユーザーが音声の開始を待つ時間を大幅に短縮できました。
音声品質の調整
Supertonicでは、サンプリングレートやビット深度を調整することで、音声品質とファイルサイズのバランスを取ることができます。
const tts = new Supertonic({
modelPath: './models/supertonic-en-us.onnx',
sampleRate: 44100, // 高品質設定
bitDepth: 16
});サンプリングレートを22050Hzから44100Hzに上げることで、音声品質が向上しますが、処理時間とファイルサイズも増加します。
用途に応じて適切な設定を選択することが重要です。
マルチスピーカー対応
Supertonicは複数の話者モデルをサポートしており、異なる声質の音声を生成できます。
const tts = new Supertonic({
modelPath: './models/supertonic-en-us.onnx',
speakerId: 'speaker_001' // 話者IDを指定
});
const audioBuffer = await tts.synthesize('Hello, world!');私が関わったプロジェクトでは、ナレーション用とキャラクター用で異なる話者モデルを使い分けることで、コンテンツの表現力を高めました。
エラーハンドリングとフォールバック
本番環境では、モデルの読み込み失敗やメモリ不足などのエラーに対する適切なハンドリングが必要です。
async function safeSynthesize(text) {
try {
const tts = new Supertonic({
modelPath: './models/supertonic-en-us.onnx',
sampleRate: 22050
});
return await tts.synthesize(text);
} catch (error) {
console.error('TTS synthesis failed:', error);
// フォールバック処理(例: クラウドAPIへの切り替え)
return await fallbackToCloudTTS(text);
}
}エラー発生時にクラウドTTSにフォールバックする仕組みを実装することで、システムの可用性を高めることができます。
Clean Code アジャイルソフトウェア達人の技のようなパフォーマンス最適化の知識があると、ユーザー体験を向上させる実装パターンが見えてきます。
Docker Compose本番運用実践ガイド:マルチコンテナ環境の監視とログ管理を効率化する設計では、本番環境での運用パターンを解説しています。

まとめ
Supertonicを使ったオンデバイスTTSの実装について、基本的な設定から最適化まで解説しました。
最低限やっておきたいことは、npmパッケージのインストールと基本的な音声合成コードの実装です。
まずはCPU環境で動作確認を行い、レスポンスタイムやメモリ使用量を測定してください。
余力があれば試してほしいことは、GPUアクセラレーションの有効化とストリーミング音声合成の実装です。
これらの最適化により、ユーザー体験を大幅に向上させることができます。
Supertonicは、クラウドAPIに依存せずにリアルタイム音声合成を実現できる強力なツールです。
オフライン環境での動作やプライバシー保護が求められるプロジェクトでは、特に有効な選択肢となります。
まずは小規模なプロトタイプから始めて、パフォーマンス要件に応じて最適化を進めていくアプローチをお勧めします。









