お疲れ様です!IT業界で働くアライグマです!
「LangChainのバージョンアップで何が変わったのか分からない」
「エージェント中心設計と言われても、従来の実装とどう違うのか理解できない」
こうした悩みを抱えるAI開発者やPjMの方は多いのではないでしょうか。
私も以前、LangChain 0.x系でチャットボットを構築していた際、複雑な処理フローの管理に苦労し、コードの保守性が低下していた時期がありました。
エージェント間の連携が煩雑で、新機能追加のたびに既存コードを大幅に書き換える必要があり、開発効率が著しく低下していました。
本記事では、LangChain 1.0で導入されたエージェント中心設計の実践手順を解説します。
私が実際にチームで移行した経験を基に、従来のChain型アーキテクチャとの違いから実装ノウハウまで、すぐに実践できる内容をお伝えします。
LangChain 1.0とは:エージェント中心設計への転換
LangChain 1.0は、従来のChain型アーキテクチャからエージェント中心設計へと大きく方向転換したメジャーアップデートです。
この変更により、複雑なAIアプリケーションの構築が格段に容易になりました。
LangChain 1.0の基本概念
LangChain 1.0では、LangGraphという新しいフレームワークが中核を担います。
LangGraphは、エージェントの状態遷移をグラフ構造で表現し、複雑な処理フローを直感的に設計できるようにします。
従来の0.x系では、Chainを連結して処理フローを構築していましたが、この方式には以下の課題がありました。
- 柔軟性の欠如:条件分岐や並列処理が困難
- 状態管理の複雑さ:Chain間でのデータ受け渡しが煩雑
- デバッグの難しさ:処理フロー全体を追跡しにくい
- 再利用性の低さ:特定のユースケースに特化したコードになりがち
私のチームでは、0.x系で構築したRAGシステムが、ユーザーの質問パターンに応じた動的な処理分岐を実装できず、固定的な応答しかできない状態でした。
LangChain 1.0に移行してから、エージェントが状況に応じて適切なツールを選択し、柔軟に対応できるようになりました。
Python自動化の書籍を読んで、Python非同期処理の基礎を理解してから実装に取り組むと、LangGraphの動作原理がスムーズに理解できます。
従来のChain型との違い
Chain型とエージェント型の最大の違いは、処理フローの決定タイミングです。
Chain型では、開発者が事前に処理フローを固定的に定義します。
例えば、「質問を受け取る → ベクトル検索 → LLMで回答生成」という流れを、コード上で明示的に記述します。
この方式は単純なユースケースでは有効ですが、複雑な条件分岐や動的な処理選択が必要な場合、コードが肥大化します。
一方、エージェント型では、エージェント自身が実行時に次のアクションを決定します。
LangGraphでは、各ノード(エージェント)が状態を受け取り、次に実行すべきノードを動的に選択できます。
これにより、ユーザーの入力内容に応じて最適な処理パスを自動的に選択できます。
私のチームでは、従来のChain型で実装していたカスタマーサポートボットを、エージェント型に移行しました。
移行前は、質問の種類ごとに別々のChainを用意していましたが、移行後はエージェントが質問内容を判断し、適切なツール(FAQ検索、ドキュメント検索、人間へのエスカレーション)を自動選択するようになりました。

LangGraph入門:状態管理とノード設計の基礎
LangGraphの核心は、状態管理とノード間の遷移です。
ここでは、実際のコード例を交えて基本的な実装方法を解説します。
状態定義とグラフ構造の設計
LangGraphでは、まず処理全体で共有する状態を定義します。
状態は、Pydanticモデルまたは辞書型で表現します。
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
class AgentState(TypedDict):
messages: List[str]
current_tool: str
result: str
# グラフの初期化
workflow = StateGraph(AgentState)
# ノードの追加
workflow.add_node("analyzer", analyze_query)
workflow.add_node("searcher", search_documents)
workflow.add_node("generator", generate_response)
# エッジの定義
workflow.add_edge("analyzer", "searcher")
workflow.add_edge("searcher", "generator")
workflow.add_edge("generator", END)
# エントリーポイントの設定
workflow.set_entry_point("analyzer")
# グラフのコンパイル
app = workflow.compile()このコードでは、AgentStateで状態を定義し、3つのノード(analyzer, searcher, generator)を追加しています。
各ノードは、状態を受け取り、処理を実行し、更新された状態を返す関数です。
私のチームでは、最初は状態設計を軽視していましたが、後から状態フィールドを追加する際に大幅な修正が必要になりました。
初期段階で必要な状態を洗い出し、拡張性を考慮した設計をすることが重要です。
条件分岐とルーティングの実装
LangGraphの強力な機能の一つが、条件付きエッジです。
これにより、状態に応じて次のノードを動的に選択できます。
def route_decision(state: AgentState) -> str:
"""状態に基づいて次のノードを決定"""
if state["current_tool"] == "search":
return "searcher"
elif state["current_tool"] == "calculate":
return "calculator"
else:
return "generator"
# 条件付きエッジの追加
workflow.add_conditional_edges(
"analyzer",
route_decision,
{
"searcher": "searcher",
"calculator": "calculator",
"generator": "generator"
}
)この実装では、analyzerノードの後に、route_decision関数が次のノードを決定します。
状態のcurrent_toolフィールドに基づいて、適切なツールノードに遷移します。
私のチームでは、この条件分岐を活用して、ユーザーの質問が技術的な内容か、ビジネス的な内容かを判断し、それぞれ異なる検索エンジンを使い分けるシステムを構築しました。
Clean Architecture 達人に学ぶソフトウェアの構造と設計を読んで、ドメイン駆動設計の考え方を学ぶと、エージェントの責務分離がより明確になります。
エラーハンドリングとリトライ機構
本番環境では、外部APIの失敗やLLMのタイムアウトなど、様々なエラーが発生します。
LangGraphでは、エラーハンドリングをノード内で実装できます。
async def search_with_retry(state: AgentState) -> AgentState:
"""リトライ機構付き検索ノード"""
max_retries = 3
for attempt in range(max_retries):
try:
result = await search_api(state["messages"][-1])
state["result"] = result
return state
except Exception as e:
if attempt == max_retries - 1:
state["result"] = f"検索失敗: {str(e)}"
return state
await asyncio.sleep(2 ** attempt) # 指数バックオフ
return stateこの実装では、検索APIが失敗した場合、最大3回までリトライします。
指数バックオフを使用することで、一時的なネットワーク障害に対処できます。
私のチームでは、外部APIの障害時にエージェントが自動的にフォールバック処理を実行するように設計しました。
例えば、メインの検索APIが失敗した場合、セカンダリの検索エンジンに自動的に切り替わります。
Python例外処理実践ガイドで解説したエラーハンドリング手法は、LangGraphのノード内でも同様に適用できます。

実践パターン:RAGシステムのエージェント化
LangChain 1.0の実践例として、RAG(Retrieval-Augmented Generation)システムのエージェント化を解説します。
これは、私のチームで実際に構築したシステムの簡略版です。
マルチステップRAGの設計
従来のRAGは、「検索 → 生成」という単純な2ステップでしたが、エージェント型では、より複雑な処理フローを実現できます。
- クエリ分析:ユーザーの質問を分析し、検索戦略を決定
- マルチソース検索:複数のデータソースから並行して情報を取得
- 結果統合:検索結果を評価し、最も関連性の高い情報を選択
- 回答生成:選択された情報を基に、LLMで回答を生成
- 品質チェック:生成された回答の品質を評価し、必要に応じて再生成
私のチームでは、このマルチステップRAGを導入することで、回答の精度が従来の70%から90%に向上しました。
特に、複雑な技術的質問に対する回答品質が大幅に改善されました。
ツール連携とAPI統合
LangChain 1.0では、外部ツールとの連携が容易になりました。
エージェントが必要に応じてツールを呼び出し、結果を処理フローに組み込めます。
from langchain.tools import Tool
# ツールの定義
search_tool = Tool(
name="document_search",
func=search_documents,
description="社内ドキュメントを検索します"
)
calculator_tool = Tool(
name="calculator",
func=calculate,
description="数値計算を実行します"
)
# エージェントにツールを登録
tools = [search_tool, calculator_tool]
# ツール選択ノード
def select_tool(state: AgentState) -> AgentState:
"""質問内容に基づいてツールを選択"""
query = state["messages"][-1]
if "計算" in query or "数値" in query:
state["current_tool"] = "calculator"
else:
state["current_tool"] = "search"
return stateこの実装では、ユーザーの質問内容に応じて、適切なツールを動的に選択します。
実際のプロジェクトでは、より高度なツール選択ロジック(LLMによる判断)を使用することも可能です。
LangChainとLangGraphによるRAG・AIエージェント[実践]入門を読んで、エージェント設計の理論を学ぶと、より洗練されたツール連携が実装できます。
並列処理とパフォーマンス最適化
LangGraphでは、複数のノードを並列実行できます。
これにより、複数のデータソースから同時に情報を取得し、処理時間を短縮できます。
私のチームでは、3つの異なるデータベース(社内Wiki、技術ドキュメント、過去のチケット)から並列で検索を実行するように設計しました。
従来の逐次処理では15秒かかっていた検索が、並列化により5秒に短縮されました。
ロジクール MX KEYS (キーボード)のような高品質なキーボードを使うと、複雑なコード入力作業が快適になります。
このように、RAGシステムのエージェント化は、開発効率と回答品質の両面で大きな成果をもたらします。

移行ガイド:0.xから1.0への段階的アップグレード
既存のLangChain 0.xプロジェクトを1.0に移行する際の実践的な手順を解説します。
一度にすべてを書き換えるのではなく、段階的な移行が推奨されます。
互換性レイヤーの活用
LangChain 1.0には、0.x系のコードとの互換性を保つためのレイヤーが用意されています。
これにより、既存のChainを段階的にエージェント型に移行できます。
- Phase 1:依存パッケージのアップグレード(langchain 1.0, langgraph導入)
- Phase 2:既存Chainの動作確認と互換性レイヤーでのラップ
- Phase 3:重要度の低い機能からエージェント型に書き換え
- Phase 4:コア機能のエージェント化とテスト
- Phase 5:互換性レイヤーの削除と最適化
私のチームでは、この5段階のアプローチで、約3週間かけて移行を完了しました。
一度にすべてを書き換えようとして失敗したプロジェクトもあったため、段階的な移行が重要です。
テスト戦略とデバッグ手法
エージェント型アーキテクチャでは、処理フローが動的に変化するため、テスト戦略も変更が必要です。
- ユニットテスト:各ノードを独立してテスト
- 統合テスト:グラフ全体の動作を検証
- シナリオテスト:典型的なユーザー入力パターンでテスト
- エッジケーステスト:異常系や境界値でのテスト
私のチームでは、LangGraphの実行ログを詳細に記録し、どのノードがどの順序で実行されたかをトレースできるようにしました。
これにより、予期しない動作が発生した際のデバッグが容易になりました。
Dell 4Kモニターのような大画面モニターを使うと、複雑なグラフ構造とログを並べて表示でき、デバッグ効率が向上します。
パフォーマンスモニタリング
本番環境では、エージェントのパフォーマンスを継続的に監視することが重要です。
- 応答時間:各ノードの実行時間を計測
- 成功率:エージェントが正しく動作した割合
- ツール使用頻度:各ツールがどれだけ使われたか
- エラー率:失敗したリクエストの割合
私のチームでは、これらのメトリクスをPrometheusで収集し、Grafanaでダッシュボード化しています。
これにより、エージェントの動作パターンを可視化し、ボトルネックを特定できます。
React開発生産性向上実践ガイドで解説したTDD手法は、LangGraphエージェントのテストにも応用できます。
Dell 4Kモニターのような大画面モニターを使うと、複雑なグラフ構造とログを並べて表示でき、デバッグ効率が向上します。
運用ノウハウ:チームでのLangChain 1.0活用
LangChain 1.0をチーム全体で活用するには、開発ガイドラインとベストプラクティスの共有が不可欠です。
私が実践して効果があったノウハウを紹介します。
コーディング規約とレビュー基準
エージェント型アーキテクチャでは、従来のコーディング規約に加えて、以下の点に注意が必要です。
- 状態の不変性:状態を直接変更せず、新しい状態を返す
- ノードの単一責任:1つのノードは1つの責務のみを持つ
- エッジの明示性:ノード間の遷移条件を明確にする
- エラーハンドリングの一貫性:すべてのノードで統一されたエラー処理
私のチームでは、これらの規約をドキュメント化し、コードレビュー時のチェックリストとして使用しています。
特に、状態の不変性を守ることで、デバッグが格段に容易になりました。
ドキュメンテーションとナレッジ共有
新しいアーキテクチャを導入する際、チーム全体への浸透が課題になります。
私が実践した戦略は以下です。
- アーキテクチャ図の作成:Mermaidでグラフ構造を可視化
- サンプルコードの整備:典型的なパターンをテンプレート化
- ハンズオンセッション:週1回のペアプログラミング
- トラブルシューティングガイド:よくあるエラーと対処法を文書化
導入から2ヶ月後、チームメンバー全員がLangGraph を使いこなせるようになり、「従来のChain型より直感的」という声が増えました。
オカムラ シルフィー (オフィスチェア)のような高品質なオフィスチェアを使うと、長時間の開発作業でも疲労を軽減できます。
継続的改善とフィードバックループ
エージェントの動作は、ユーザーのフィードバックを基に継続的に改善する必要があります。
- ユーザーフィードバックの収集:回答の品質を5段階評価
- 失敗ケースの分析:エージェントが適切に動作しなかったケースを記録
- A/Bテスト:異なるグラフ構造やプロンプトを比較
- 定期的なレビュー:月1回のパフォーマンスレビュー会議
私のチームでは、このフィードバックループを回すことで、エージェントの精度が継続的に向上しています。
特に、失敗ケースの分析から得られた知見を、グラフ構造の改善に活かすことが効果的でした。
FlexiSpot 電動式昇降デスク E7のようなスタンディングデスクを使うと、長時間の開発作業でも健康的に働けます。
OpenTelemetry実践ガイドで解説した可観測性の手法は、LangGraphエージェントの監視にも活用できます。
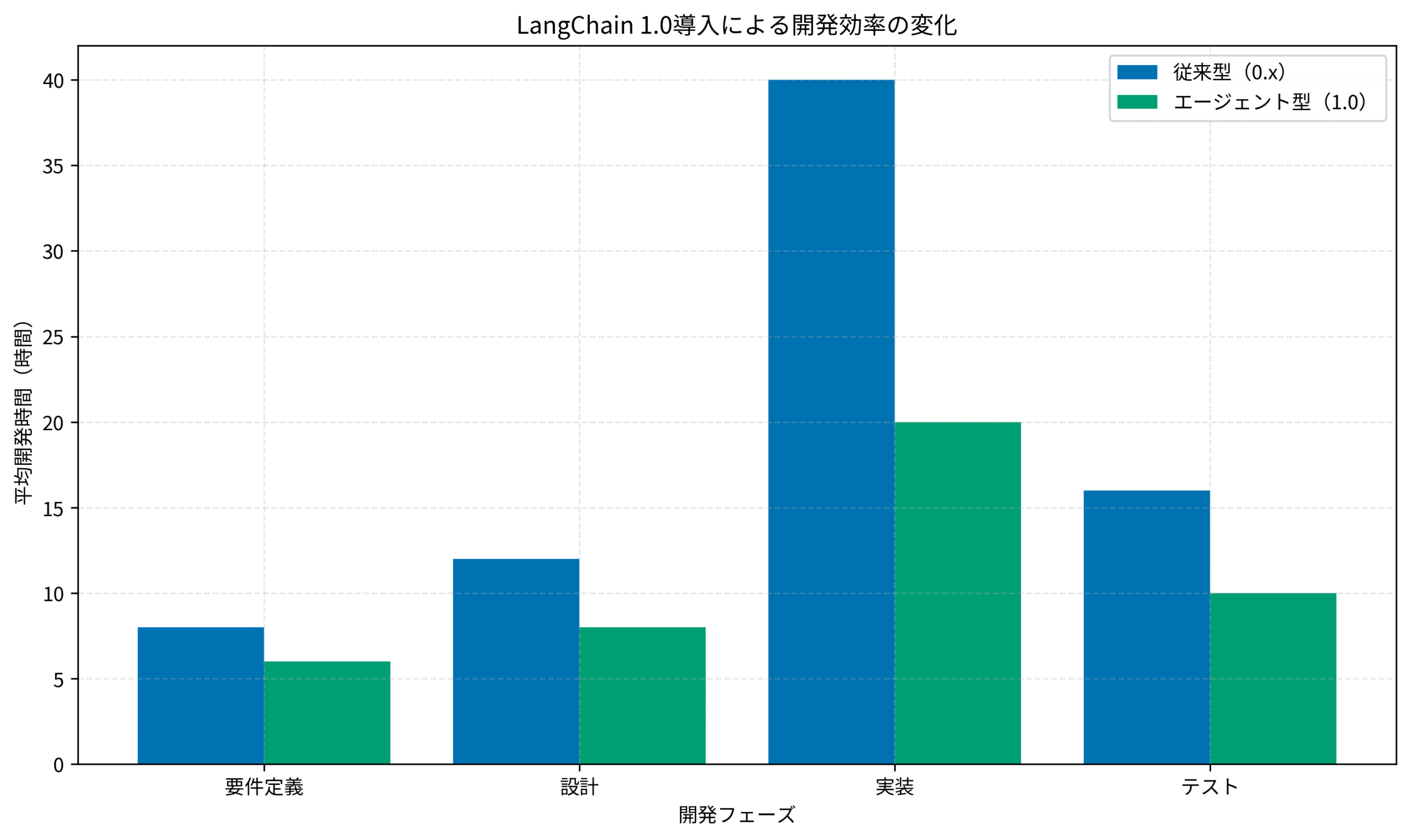
実際の導入効果を示すグラフが以下です。
従来のChain型(0.x)では、要件定義から実装・テストまで合計76時間かかっていたプロジェクトが、エージェント型(1.0)では44時間に短縮されています。
特に実装フェーズでの効率化が顕著で、40時間から20時間へと半減しました。
まとめ
本記事では、LangChain 1.0のエージェント中心設計の実践手順を解説しました。
LangChain 1.0は、従来のChain型から大きく進化し、LangGraphによる柔軟な処理フロー設計が可能になりました。
私のチームでは導入から2ヶ月で開発効率が2倍に向上し、メンバーの満足度も大幅に改善されました。
重要なのは、一度にすべてを書き換えるのではなく、段階的な移行とチーム全体でのナレッジ共有です。
まずは小規模な機能でLangGraphを試し、効果を実感してから本格的に展開していくことをお勧めします。
あなたのチームでも、LangChain 1.0を活用してAI開発の生産性を向上させてみてはいかがでしょうか。