
こんばんは!IT業界で働くアライグマです!
「インデックス貼ったのに全然速くならない…もうデータベース信じられない!」
データベースを扱うエンジニアなら、一度は似たような悩みを抱えたことがあるのではないでしょうか。
私自身、過去に運用していたECサイトで、ユーザー数が10倍に増えた瞬間にデータベースが悲鳴を上げ、深夜まで緊急対応に追われた経験があります。
当時は「設計時にもっと慎重にやっておけば…」と何度も後悔しました。
本記事では、データベース沼にハマる典型的なパターンと、そこから抜け出すための実践的な手法を解説します。
PjMとして複数のプロジェクトで培った意思決定基準も交えながら、あなたのデータベース設計・運用の改善に役立つ知見をお届けします。
下記グラフは、プロジェクトフェーズごとのDB問題解決時間の推移を示しています。
設計段階では2時間で解決できた問題が、スケール対応時には72時間かかるケースも珍しくありません。
早期の適切な設計がいかに重要か、数値で確認できます。
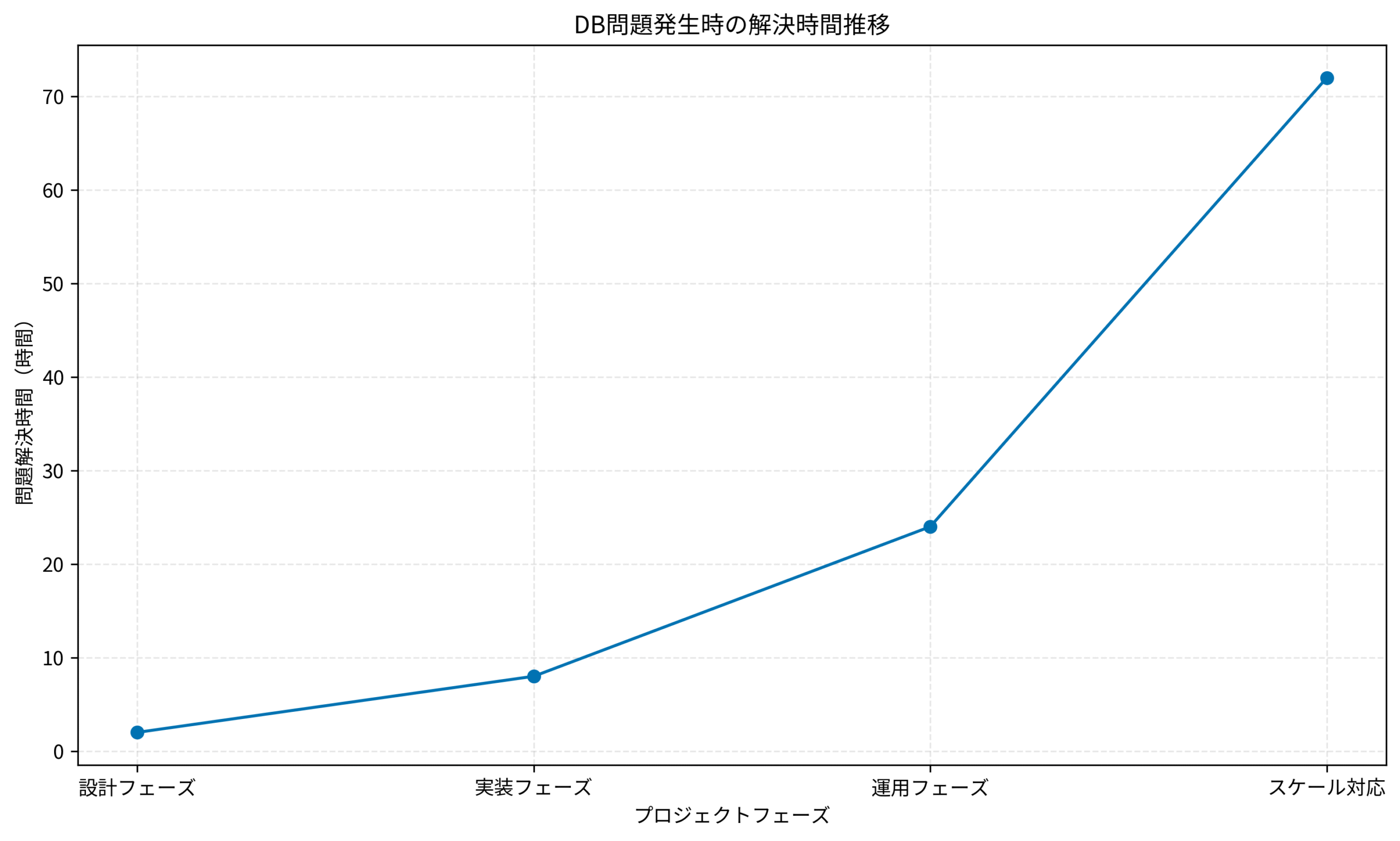
データベース沼にハマる典型的なパターン
データベースを扱う上で、特にエンジニアを苦しめる問題にはいくつかの共通点があります。
ここでは、実際に多くのエンジニアが遭遇した「データベース沼」にハマる典型的なパターンを、私の実体験を交えて紹介します。
設計ミスが後々の爆弾に
アプリケーション開発の初期段階では、「とりあえず動くものを作る」ことが優先され、データベース設計が後回しにされることがよくあります。
しかし、データベースの設計ミスは後々の技術的負債となり、修正が非常に困難になります。
私が以前担当したプロジェクトでは、MVP開発時に「VARCHAR(255)で全部いけるでしょ」と安易に決めた結果、後から数値計算が必要になった際に型変換地獄に陥りました。
テーブル設計を見直すには、本番データの移行リスクや関連コードの修正工数が膨大で、結局そのまま運用を続けざるを得なかったのです。
よくある設計ミスには以下のようなパターンがあります。
- 正規化しすぎてJOIN地獄:複雑な結合処理でパフォーマンスが低下
- 正規化を怠り冗長なデータ構造:データの整合性が崩れるリスク増大
- カラムのデータ型を適当に選択:型変換や範囲制約の問題が後から発覚
- IDのオートインクリメント設計:スケールアウト時に分散IDの再設計が必要に
開発初期の段階で適切な設計を行わなかった結果、後になって「なぜこんな設計にしたんだ…」と後悔するのは、データベース沼あるあるの一つです。
設計時の判断基準として、リファクタリングの知識が役立ちます。
リファクタリング(第2版)
データベースの種類ごとの特性を理解することも重要です。詳しくはプログラマーのための効率的なデバッグ手法やデータベースの種類完全ガイドで解説しています。
意思決定基準:MVP段階でも将来のスケールを見越し、最低限の正規化とデータ型選定は慎重に行う
インデックスの罠
インデックスはデータベースのパフォーマンスを向上させるために不可欠な要素ですが、適当に追加すると逆に遅くなることもあります。
私のチームでは、ある日突然「書き込みが遅い」とアラートが鳴り響きました。
調査すると、過去のメンバーが「念のため」と複数カラムに大量のインデックスを貼っており、INSERT/UPDATEのたびにインデックス再構築のオーバーヘッドが発生していたのです。
不要なインデックスを削除したところ、書き込み速度が3倍に改善しました。
インデックスの典型的な問題は以下の通りです。
- インデックスを付けすぎて更新処理が遅延:INSERT/UPDATEの負荷増大
- クエリに適していないインデックス作成:検索に全く使われず無駄なストレージ消費
- LIKE ‘%文字列%’ でインデックスが効かない:フルスキャンが発生し応答時間が数十秒に
インデックスは万能ではなく、適切な設計と検証が必要です。
「インデックスを貼れば速くなる」という考えが逆効果になり、「インデックスが足かせになった…」と後悔するエンジニアは後を絶ちません。
意思決定基準:インデックスはEXPLAINで実行計画を確認し、実際のクエリパターンに基づいて追加・削除を判断する
クエリ最適化の泥沼
ある日、エンジニアは気づきます。
「このSQL、遅くないか?」
パフォーマンスチューニングのためにEXPLAINを確認してみると、フルテーブルスキャンの文字が目に飛び込んできます。
私も以前、管理画面の一覧ページで「全データ取得→アプリ側でフィルタ」という悪夢のようなコードを見つけ、本番環境で500万レコードをSELECT *していた現場に遭遇しました。
クエリ最適化で陥りがちな問題は以下です。
- SELECT * を多用:不要なカラムまで取得しネットワーク帯域を圧迫
- GROUP BY や ORDER BY でメモリ消費:一時テーブル作成でディスクI/O増加
- ネストしたサブクエリが爆発:非効率な処理で応答時間が数分に
- N+1クエリ問題:ループ内でクエリ発行し数千回のDB呼び出し
チューニングのために試行錯誤を繰り返し、最終的に「もうMySQL(PostgreSQL、MongoDB…)を信じられない」と呟くエンジニアが後を絶ちません。
システムアーキテクチャ全体の知識があると、適切な最適化判断ができます。
ソフトウェアアーキテクチャの基礎
意思決定基準:クエリ改善は測定可能な指標(応答時間・スロークエリログ)で効果検証し、改善幅が10%未満なら別の施策を検討する
スケールアウトとレプリケーションの罠
シンプルなシステムでは単一DBで問題ありませんが、サービスが成長するにつれて「スケールアウト」の課題が浮上します。
私が担当したSaaSプロジェクトでは、ユーザー数が急増した際にリードレプリカを導入しました。
しかし、マスター・スレーブ間のレプリケーション遅延が発生し、「さっき登録したデータが見えない!」というユーザーからのクレームが殺到しました。
結局、重要な書き込み後の読み取りは強制的にマスターを参照する仕組みを追加し、レプリカ活用の効果が半減する結果になりました。
スケールアウトの典型的な課題は以下です。
- シャーディング設計の難航:ユーザーIDで分割?地域ごと?最適な分割軸の決定に数週間
- リードレプリカの同期遅延:データの整合性とパフォーマンスのトレードオフ
- 書き込み負荷の集中:スケールアップしか選択肢がなくコスト増大
スケールアウトを決断したのに、運用が複雑になりすぎて後悔するパターンも多いのです。
意思決定基準:スケールアウトは現状の3倍負荷まで耐えられる設計にし、それ以上はアーキテクチャ全体の見直しを優先する

データベース沼から抜け出すために
では、どのようにすればデータベースの沼から抜け出すことができるのでしょうか。
ここでは、私が実際にプロジェクトで実践してきた具体的な改善手法を紹介します。
設計を慎重に行う
データベース設計は後からの修正が困難なため、初期段階での慎重な検討が不可欠です。
私のチームでは、新規プロジェクト開始時に必ずER図レビュー会を開催しています。
エンジニア・PdM・デザイナーが集まり、「このカラムは本当に必要か?」「将来的にどう拡張するか?」を議論します。
この取り組みにより、後から「テーブル設計ミスでリリース延期」という事態を回避できています。
設計時の重要ポイントは以下です。
- 正規化と非正規化のバランス:読み取り頻度の高いデータは適度な非正規化も検討
- 適切なデータ型選択:数値はINT/BIGINT、日時はTIMESTAMP、可変長文字列はTEXTと使い分け
- スケーラビリティ考慮:将来の分散化を見越したUUID採用やパーティショニング設計
ドメイン駆動設計の考え方を取り入れると、ビジネスロジックとDB設計の整合性が保ちやすくなります。
ドメイン駆動設計
意思決定基準:設計レビューで3人以上のエンジニアが合意し、想定される最大データ量でのパフォーマンステストを実施する
クエリを最適化する
既存システムのクエリ改善は、即効性のある施策です。
私のチームでは、毎週スロークエリログレビューを実施し、実行時間上位10件のクエリを改善対象としています。
あるとき、1つのクエリを見直しただけで、ページ表示速度が8秒→0.5秒に改善し、ユーザー離脱率が30%減少しました。
この改善プロセスはコードレビュー効率化完全ガイドで解説している手法と同様に、体系的なアプローチが効果的です。
クエリ最適化の実践手法は以下です。
- EXPLAINで実行計画確認:インデックスが使われているか、テーブルスキャンが発生していないか検証
- 必要なカラムだけ取得:SELECT * を避け、使用するカラムを明示的に指定
- 適切なインデックス追加:WHERE句・JOIN条件・ORDER BY句で使用されるカラムに優先的に付与
データ分析基盤の知識があると、大量データの効率的な処理方法が理解できます。
[エンジニアのための]データ分析基盤入門<基本編>
意思決定基準:1秒以上かかるクエリは優先改善対象とし、改善後は本番環境で1週間モニタリングする
運用体制を整える
技術的な対策だけでなく、組織的な運用体制の整備も重要です。
私が以前所属していた企業では、DB管理者が不在で「誰もデータベースの全体像を把握していない」状態でした。
そこで、DBオーナー制度を導入し、各テーブルに責任者を割り当て、定期的なメンテナンス計画を立てるようにしました。
結果、障害発生時の復旧時間が平均4時間→1時間に短縮されました。
運用体制整備のポイントは以下です。
- スロークエリログの定期チェック:週次レビューで問題の早期発見
- データ増加を見越したリファクタリング:半年ごとにテーブル肥大化を確認し古データのアーカイブ化
- バックアップ・リストア手順の確立:障害発生時に30分以内で復旧できる体制構築
長時間のDB作業には、快適な作業環境が不可欠です。
オカムラ シルフィー (オフィスチェア)
意思決定基準:月次でDB健全性レポートを作成し、肥大化・スロークエリ・バックアップ成功率の3指標を経営層に報告する

まとめ
データベースは便利なツールである一方、適切に管理しないとエンジニアを苦しめる沼へと変貌します。
本記事で解説した重要ポイントは以下の通りです。
- 設計ミスは後々の爆弾:初期段階でER図レビューを実施し、将来のスケールを見越した設計を
- インデックスは万能ではない:EXPLAINで効果検証し、不要なインデックスは削除する勇気を
- クエリ最適化は必須:スロークエリログを定期レビューし、即効性のある改善を優先
- スケールアウトには慎重に:レプリケーション遅延やシャーディング複雑化のリスクを事前評価
データベースの沼にハマったエンジニアは数知れず、しかし適切な知識と経験を積めば、抜け出すことも可能です。
私自身、過去の失敗から学び、今では「DB設計が楽しい」と思えるようになりました。
「もうデータベースはこりごりだ!」と言いたくなる前に、本記事で紹介した実践手法を試してみてください。
きっとあなたのプロジェクトでも、データベースが強力な味方になるはずです。
最後までお読みいただき、ありがとうございました!
データベース運用の改善に向けて、一緒に取り組んでいきましょう。









