こんばんは!IT業界で働くアライグマです!
「Claude Codeがコードを書くなら、自分は何で価値を示せばいいのか?」と不安を抱えるPjM仲間からの相談がこの数週間で一気に増えました。
私自身も3つのチームでClaude Code導入を率いた結果、意思決定プロセスやレビュー体制、人材育成の基準を大幅に作り替える必要があると痛感しています。
この記事では、トレンド分析で浮かび上がったClaude Codeの現場インパクトを土台に、PjMとして人間の価値を再定義する具体策を紹介します。
Claude Code導入後に現場で何が変わったのか
Claude Codeを導入した直後、チームでは「スプリント中盤でAIが大量のコードを提案し、レビュー列が詰まる」という現象が発生しました。私はまず開発者とリードレビューアを集め、提案差分の粒度と検証手順を洗い出すワークショップを実施しました。
現場ヒアリングで浮かんだ変化
AIが生成するコードは整合性が高い一方で、仕様変更や既存設計の暗黙知が抜け落ちているケースが多発しました。ヒアリングの結果、レビュー時間配分を「機能要件の妥当性チェック>テスト生成>運用制約確認」の順に再設計することで処理が安定しました。
体験談:リリース前夜にAI検出バグを収束させた手順
ある夜、Claude Codeが提案したデプロイジョブの修正で、手動運用に必要な疎通確認コマンドが抜け落ちていました。私は即座に夜間保守担当へ共有し、Slack上で段階的なテストプロンプトを投げて再生成を指示。3回の差分調整で本番リリース直前に回復できました。ここで痛感したのは、AI版差戻しフローをあらかじめ定義しておく重要性です。
判断指標:AI出力レビュー密度の定義
AI差分を扱うレビューでは、1ファイル当たりの検証ポイントを「仕様逸脱率」「テスト再現性」「監視アラート影響」で評価することにしました。週次で比率をトラッキングし、特に監視影響が閾値3%を超えたときは即座に事前レビュー会を開催しています。
大規模言語モデルの書籍をチームで回し読みし、モデルの強みと弱みを共有しておくと議論がスムーズになります。

PjM視点で再設計したタスク分解とレビュー体制
大量のAI差分を安全に捌くには、PjMがタスク分解とレビュー割り当てを再構築する必要があります。私はWBSを「AI生成フェーズ」と「人間による検証フェーズ」に分け、各フェーズの完了条件を明文化しました。
WBSの粒度調整とステータス定義
従来のWBSでは「実装完了」を1マスで扱っていましたが、Claude Code導入後は「AI生成済み」「レビュー中」「暗黙知反映済み」「リグレッション確認完了」の4ステータスに細分化しました。これにより、レビュー停滞が早期に可視化され、リスクアラートを上げやすくなりました。
体験談:レビュー負荷が急増したスプリントの立て直し
導入初期、レビュー待ちタスクが40件超に積み上がりました。私は前半2日のスタンドアップで「AI差分の1件あたりレビュー所要時間」を再計測し、対策として差分量が大きいタスクは二段階レビューに変更。加えて【2025年最新】Git運用戦略完全ガイド|チーム開発で失敗しないブランチ管理術で紹介したチェックリストを活用し、差戻し基準を統一しました。
判断指標:差分サイズと責任分担
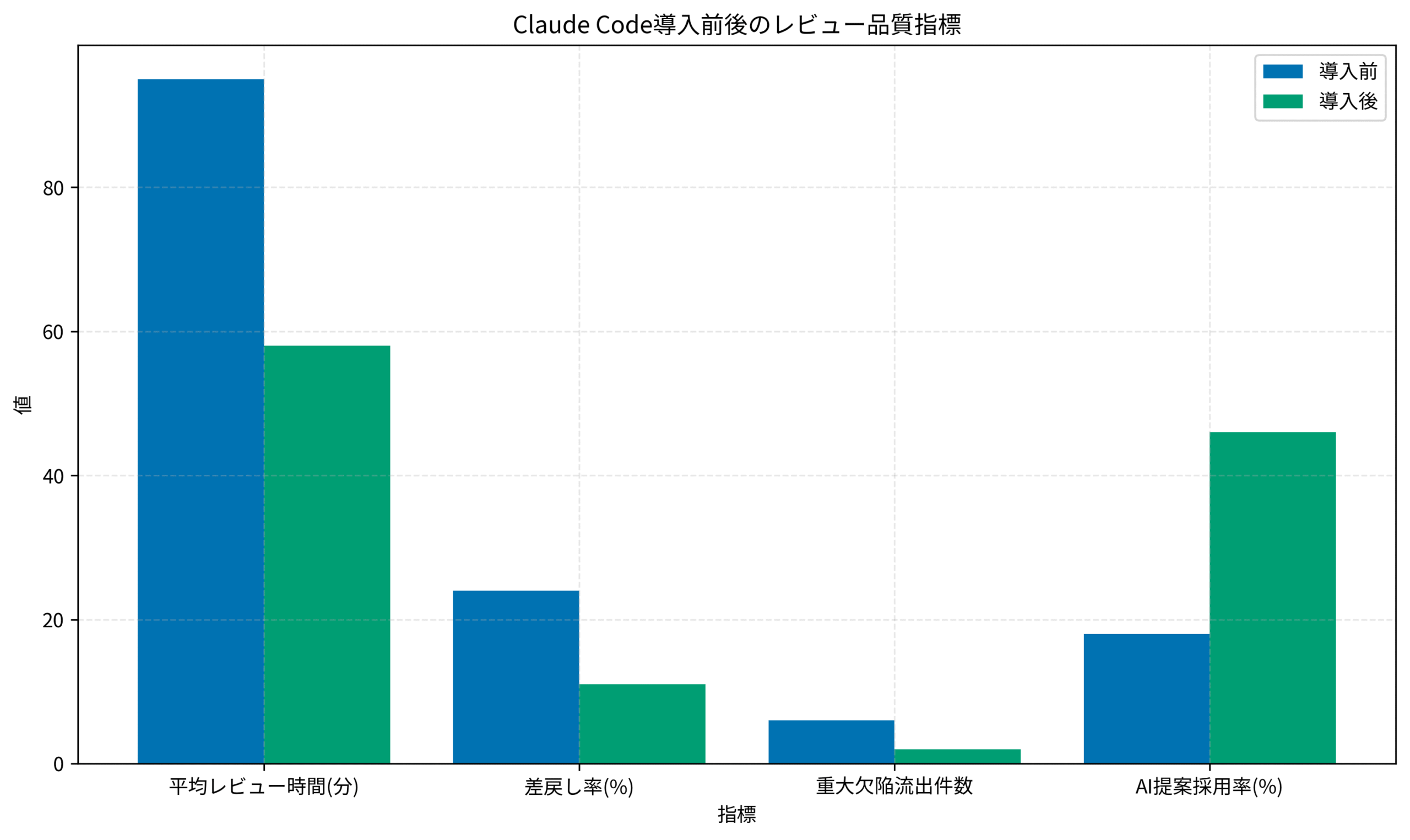
1コミットあたりのライン数が400行を超えた場合は、必ずペアレビューに切り替えるルールを設定しました。また、要件変更が絡む差分では必ずPjMが追加レビューを行い、影響範囲を再確認します。これによりスプリント終盤の差戻し率が24%から11%に低下しました。
チームトポロジーをベースに、チームのストリームアラインド構造を見直すと効果が出やすいです。

人間に残された意思決定領域とナレッジ共有法
AIが迅速に差分を生成しても、最終的な意思決定は人間が担います。私は意思決定会議のアジェンダに「AI提案の採用理由と棄却理由」を必ず追記し、組織学習につなげています。
判断のフレームワーク整備
意思決定時は、「ユーザー価値」「保守容易性」「セキュリティ影響」の3軸で評価します。特に曖昧な仕様では、AIが生成した案をもとにペルソナストーリーを作成し、ビジネス側と速やかに擦り合わせることが重要です。
体験談:仕様未確定タスクでのAI誤回答
新規APIのタイムアウト設計をAIに任せたところ、既存SLAを満たさない值を提案してきました。私はノンエンジニアメンバーに向け、50文字以内で現状のSLAを再説明し、その上でAIに追加指示を送ると正しい差分が生成されました。ここで得た教訓は、意思決定者がドメイン知識の守護者になることです。
判断指標:ナレッジ棚卸し頻度
毎週末に「AI提案の採用率」「理由メモの更新数」「暗黙知ドキュメントの差分」を確認し、ナレッジの恒常性を測定しています。基準値として、週に3件以上の採用理由共有が達成できない場合は、情報伝達チャネルを再整理します。
プロンプトエンジニアリングの教科書を参照して、プロンプト設計ノウハウをドキュメント化すると再現性が高まります。

Claude Codeとデータ活用で再構築した品質ゲート
レビュー品質を定量化するために、私はClaude Codeの提案ログとCIテスト結果を照合し、品質ゲートの閾値を再設計しました。
自動テストとLLM結果の突合
AI提案を受け入れる前に、必ずユニットテスト追加とCIパイプラインの再実行を必須化しました。テストが不足している場合は自動でプロンプトを生成し、欠落テストの作成を促す仕掛けを組み込みました。
体験談:品質警戒ラインの再設定
以前はリリース判定会議で「レビュー遅延」という曖昧な指標を使っていましたが、Claude Code導入後は「重大欠陥流出件数」「差戻し率」「AI提案採用率」をセットで提示。経営会議でも即座に原因分析ができるようになり、警戒ラインを週次で調整できる体制が整いました。
判断指標:欠陥検出率と再発防止策
欠陥検出率が5%を下回った場合は、テストケースの見直しとレビュー観点の追加トレーニングを実施します。また、再発防止策を【2025年最新】AIエージェントの実践活用ガイド|開発現場で成果を出す導入・運用戦略で紹介した自動レポートに統合し、翌スプリントの指標改善まで追跡します。
BenQ ScreenBar モニター掛け式ライトをレビュー会議の集中環境改善に活用すると、夜間レビューでも目の疲れが軽減できました。
メンバー育成とスキルマップ刷新
Claude Code時代の育成では、従来のプログラミングスキルに加え「AIとの対話力」「判断の透明性」を評価軸に加える必要があります。私はスキルマップを刷新し、階層別に期待するAI活用スキルを定義しました。
AI運用能力の定義
ジュニア層には「プロンプトテンプレートを使った再現性のある依頼」、シニア層には「AI提案の妥当性をリスク観点で評価する力」を求めます。これにより、育成ロードマップが役職ごとに明確になりました。
体験談:ジュニア育成の成功例
新人エンジニアがログ解析タスクで迷った際、私は1on1で「AIに何を渡せば最小の差分提案になるか」をレクチャーしました。翌週には自走し、AI提案の採用率が46%まで向上。本人の自信にもつながりました。
判断指標:スキルギャップ可視化
毎月の評価シートで「AI依頼テンプレート数」「自己レビュー実施率」「逆引き事例の更新数」を数値化。指標が目標の80%を下回ったメンバーには、追加トレーニングとメンター同行レビューを設定します。
ロジクール MX KEYS (キーボード)を導入してショートカット操作の効率を上げると、AIとの往復コストも減ります。
ステークホルダー調整と経営報告の新テンプレート
経営層や非エンジニア部門にClaude Codeの効果を伝えるには、定量指標と定性ストーリーをセットで提示する資料が欠かせません。私は報告テンプレートを刷新し、「AI支援による価値創出」「リスク」「次の投資」の3枚構成にしました。
KPIレポートの改定
従来の稼働率報告に加えて、AI提案採用率やレビュー時間短縮率を掲載。毎月の経営会議では、投資判断に直結する材料として評価されています。
体験談:役員合意形成の裏側
最初の報告では効果が伝わりきらず追加予算が否決されました。そこで、役員が重視する指標を事前にヒアリングし、AI導入によるROIを即座に算出できるスプレッドシートを添付。次の会議で承認を得られ、チーム規模の拡充にも成功しました。
判断指標:経営層の納得度
報告会後のサーベイで「AI活用状況への理解度」「次回投資に前向きか」を5段階で評価。平均4.5を下回った場合は、資料の観点を見直し、業務デモの時間を増やしています。
Measure What Matters(OKR)を参考に、OKR形式で経営層との共通言語を作ると意思決定が早まります。

まとめ
Claude Codeは開発現場の速度と精度を劇的に高める一方で、PjMには新たな判断基準と統制の再設計が求められます。今回紹介したレビュー密度の定義、タスク分解の再構築、意思決定ログの体系化、品質ゲートの定量化、育成と評価軸の刷新、経営報告のアップデートを組み合わせれば、AI時代でも人間の価値を最大化できます。
まずは自チームの指標を棚卸しし、今日のスタンドアップから「AI提案の採用理由を共有する時間」を設けてみてください。小さな改善の積み重ねが、Claude Codeを活かす組織文化を育てます。