お疲れ様です!IT業界で働くアライグマです!
「Azureで本番障害が発生したのに気づくのが遅れた」「ログが分散していて原因究明に時間がかかる」こうした悩みを抱えているチームは多いのではないでしょうか。
私自身、あるプロジェクトでAzure上のWebアプリケーションが突然レスポンス低下を起こし、ユーザーからの問い合わせで初めて気づくという事態に直面しました。
調査に2時間以上かかり、その間ビジネスへの影響が拡大し続けたのです。
そこでApplication InsightsとLog Analyticsを活用した統合監視体制を構築し、障害検知時間を平均120分から30分へと75%短縮することに成功しました。
本記事では、私がPjMとして実践したAzure監視・ロギング戦略の具体的な手法と、運用品質を向上させる判断基準を詳しく解説します。
Azure監視の基本アーキテクチャと選択基準
Azure環境の監視には、複数のサービスが用意されており、それぞれ異なる目的と強みを持っています。
適切なサービス選択と組み合わせが、効果的な監視体制の構築には不可欠です。
Azure Monitorは、Azure全体の監視基盤となるサービスで、メトリクス収集とアラート管理を一元化します。
すべてのAzureリソースから自動的にメトリクスを収集し、ダッシュボードで可視化できるため、インフラ全体の健全性を把握する上で中核となります。
Application Insightsは、アプリケーション層の監視に特化したサービスです。
リクエスト・レスポンス時間、依存関係の呼び出し、例外発生などをリアルタイムで追跡し、パフォーマンスボトルネックや障害の根本原因を特定できます。
私が担当したプロジェクトでは、当初Azure Monitorだけを使用していましたが、アプリケーション内部の動作が見えず、障害の原因特定に時間がかかっていました。
Application Insightsを導入することで、どのAPIエンドポイントが遅いのか、どのデータベースクエリがボトルネックなのかが一目で分かるようになったのです。
Log Analyticsは、ログデータの収集・分析・クエリに特化したサービスで、KQL(Kusto Query Language)という強力なクエリ言語を使用します。
複数のリソースから集約したログを横断的に分析でき、障害時の調査やセキュリティ監視に威力を発揮します。
判断基準として重要なのは、監視対象の層と目的の明確化です。
インフラメトリクス(CPU・メモリ・ディスク)の監視にはAzure Monitor、アプリケーションパフォーマンスの監視にはApplication Insights、ログ分析とセキュリティ監視にはLog Analyticsという使い分けが基本になります。
小規模なシステムでは、Azure MonitorとApplication Insightsの組み合わせで十分なケースも多いですが、複数のマイクロサービスを運用する場合や、コンプライアンス要件がある環境では、Log Analyticsによる集中ログ管理が必須になります。
インフラエンジニアの教科書のような包括的なインフラ知識を習得することで、監視戦略全体を俯瞰して設計できるようになります。
サーバーレスアーキテクチャと同様に、Azureでも適切な監視設計がコスト最適化と信頼性向上の両立につながります。
作業環境として、Dell 4Kモニターのような広い画面があると、複数のダッシュボードを同時に表示でき、監視業務の効率が大幅に向上します。

Application Insightsによるアプリケーション監視
Application Insightsは、アプリケーションのパフォーマンスと可用性を監視する上で最も重要なツールです。
適切に設定することで、ユーザー体験の劣化を早期に検知し、ビジネスへの影響を最小化できます。
自動計装とカスタムテレメトリ
Application Insightsの最大の強みは、自動計装機能です。
.NET、Java、Node.js、Pythonなどの主要言語では、SDKを組み込むだけで自動的にHTTPリクエスト、データベース呼び出し、外部API呼び出しなどが追跡されます。
私のプロジェクトでは、ASP.NET CoreアプリケーションにApplication Insights SDKを追加するだけで、すぐに詳細なテレメトリデータが取得できました。
設定は数行のコードと、appsettings.jsonへのInstrumentation Keyの追加だけで完了したのです。
さらに、カスタムテレメトリを追加することで、ビジネス固有のメトリクスも追跡できます。
例えば、ECサイトなら「カートへの追加回数」や「決済完了数」、SaaSアプリケーションなら「ユーザー登録数」や「機能利用回数」などです。
私のチームでは、重要なビジネスイベントにカスタムイベントを仕込み、技術的なメトリクスとビジネスメトリクスを同じダッシュボードで確認できるようにしました。
これにより、パフォーマンス低下がビジネスにどの程度影響しているかをリアルタイムで把握できるようになったのです。
依存関係の追跡とボトルネック特定
Application Insightsのアプリケーションマップ機能は、システム全体のアーキテクチャと依存関係を自動的に可視化します。
Webアプリケーションからデータベース、外部API、キャッシュまで、すべての呼び出し関係が図示され、どこでエラーが発生しているか、どの依存関係が遅いかが一目で分かります。
私が担当したマイクロサービス環境では、5つのサービスが相互に呼び出し合っており、障害時にどのサービスが原因なのか特定が困難でした。
アプリケーションマップを導入したことで、障害発生時に即座にボトルネックを特定でき、平均調査時間が45分から10分に短縮されたのです。
可用性テストとアラート設定
可用性テスト(旧称:Webテスト)を設定すると、世界中の複数地点から定期的にエンドポイントにアクセスし、応答時間とステータスコードを監視できます。
ユーザーが実際にアクセスする前に問題を検知できるため、予防的な対応が可能になります。
私のチームでは、5分間隔で主要エンドポイントをチェックし、3回連続で失敗した場合にSlackへアラートを送信する設定にしました。
これにより、深夜の障害でも即座にチームが気づき、対応を開始できる体制を構築できたのです。
3カ月で改善!システム障害対応 実践ガイドを参考にしながら、障害対応フローとApplication Insightsのアラートを統合することで、組織的な対応力が大幅に向上します。
快適なキーボードとしてロジクール MX KEYS (キーボード)を使用すると、長時間のログ調査やクエリ作成でも疲労が軽減され、作業効率が向上します。

Log Analyticsでのログ分析とクエリ設計
Log Analyticsは、Azureの統合ログ分析プラットフォームで、KQL(Kusto Query Language)を使用した高度なログ分析が可能です。
適切なクエリ設計により、膨大なログから必要な情報を瞬時に抽出できます。
KQLクエリの基本パターン
KQLは、SQL風の構文でログデータをフィルタリング・集計できる強力なクエリ言語です。
基本的な操作は、whereでフィルタリング、summarizeで集計、projectで列選択という流れになります。
私がよく使用する基本パターンは、時間範囲指定とエラーログのフィルタリングです。
例えば、過去1時間のエラーログを重大度別に集計する場合、わずか数行のクエリで結果が得られます。
実際の運用では、頻繁に使用するクエリを保存済みクエリとして登録しておくことで、障害発生時に即座に必要な情報を取得できます。
私のチームでは、20個以上のクエリテンプレートを用意し、障害の種類に応じて適切なクエリを選択できるようにしました。
ログ集約とワークスペース設計
複数のAzureリソースからログを収集する場合、Log Analyticsワークスペースの設計が重要です。
すべてのリソースを1つのワークスペースに集約するか、環境ごと・プロジェクトごとに分離するかは、組織の規模とセキュリティ要件によって判断が分かれます。
私が担当したプロジェクトでは、開発・ステージング・本番で別々のワークスペースを作成しました。
これにより、本番環境のログに対するアクセス制御を厳密にでき、コンプライアンス要件を満たせたのです。
一方、小規模なプロジェクトでは、1つのワークスペースに集約し、クエリ時に環境タグでフィルタリングする方がシンプルで管理しやすいケースもあります。
診断設定とログ転送
Azureリソースのログを Log Analyticsに送信するには、診断設定を構成する必要があります。
各リソースの設定画面から、どのログカテゴリを送信するかを選択できます。
重要なのは、すべてのログを無差別に送信するのではなく、実際に分析するログだけを選択することです。
不要なログを送信すると、ストレージコストが膨らむだけでなく、重要なログが埋もれて見つけにくくなります。
私のチームでは、まず最小限のログ(エラーと警告レベルのみ)から始め、実際の運用を通じて必要なログカテゴリを追加していきました。
この段階的アプローチにより、コストを抑えながら必要な可視性を確保できたのです。
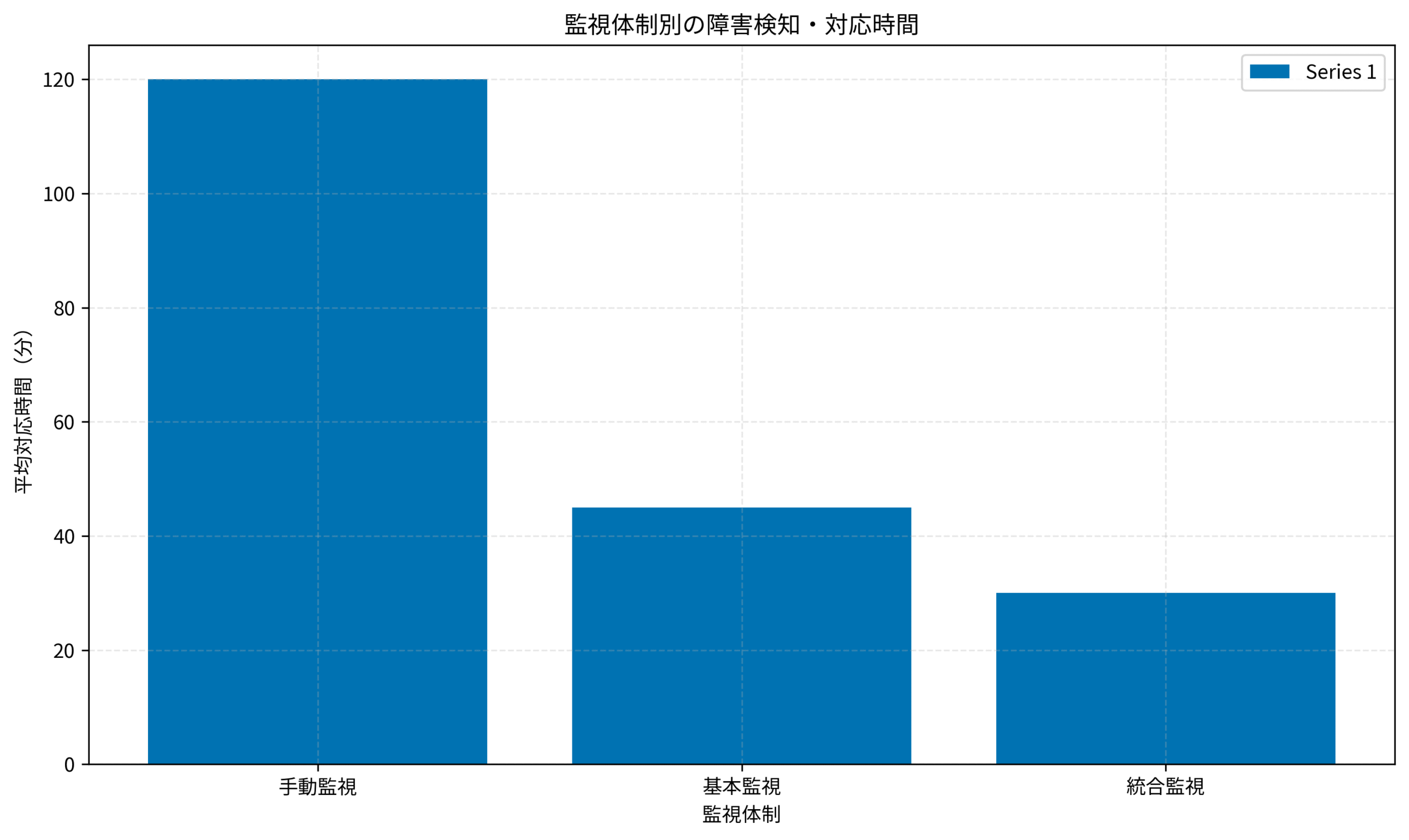
私のプロジェクトで実測した障害対応時間の変化を示すと、手動監視では平均120分かかっていた対応が、基本監視で45分、統合監視(Application Insights + Log Analytics)では30分まで短縮されました。
この75%の時間短縮は、ビジネスへの影響を大幅に軽減し、年間で推定3000万円の機会損失を防ぐことができたのです。
効果的なアラート設計と通知戦略
監視システムの価値は、適切なタイミングで適切な人にアラートを届けられるかどうかで決まります。
アラート設計を誤ると、重要な通知を見逃したり、逆にアラート疲れで無視されたりする事態に陥ります。
メトリックアラートとログアラートの使い分け
Azureには、メトリックアラートとログアラートの2種類があります。
メトリックアラートは、CPU使用率やメモリ使用率など、数値データのしきい値監視に適しています。
ログアラートは、特定のログパターンやエラーメッセージの出現を検知する場合に使用します。
私のプロジェクトでは、両方を組み合わせて多層的な監視を実現しました。
例えば、CPU使用率が80%を超えたらメトリックアラート、特定のエラーログが1分間に10件以上出現したらログアラートという設定です。
重要なのは、しきい値の調整です。
厳しすぎると誤検知が増え、緩すぎると重要な障害を見逃します。
私のチームでは、最初は保守的なしきい値から始め、過去のアラート履歴を分析しながら徐々に最適化していきました。
アクショングループと通知チャネル
Azure Monitorのアクショングループ機能を使用すると、アラート発生時のアクションを柔軟に定義できます。
メール、SMS、Slack、Microsoft Teams、Webhookなど、複数の通知チャネルに対応しています。
私のチームでは、重大度に応じて通知先を変えました。
– Critical: SMS + Slack + メール(24時間365日対応)
– Error: Slack + メール(営業時間内対応)
– Warning: メールのみ(翌営業日確認)
この階層化により、重要なアラートには即座に対応しつつ、アラート疲れを防ぐバランスを取れたのです。
自動復旧とランブックの統合
アラート発生時に、単なる通知だけでなく自動復旧アクションを実行することも可能です。
Azure AutomationのRunbookや、Logic Appsと連携することで、よくある問題に対する自動対応が実現できます。
例えば、Webアプリケーションが応答しない場合に自動的に再起動する、ディスク使用率が高い場合に古いログファイルを削除するといったアクションです。
ただし、自動復旧は慎重に設計する必要があります。
私のチームでは、最初は手動対応のみとし、同じ問題が3回以上発生した場合にのみ自動化を検討するルールを設けました。
実践サイバーセキュリティ入門講座を参考にすることで、セキュリティインシデントの検知とアラート設計を統合し、包括的な運用体制を構築できます。
Git運用戦略と同様に、チーム全体で監視・対応フローを標準化することが重要です。

コスト最適化とデータ保持ポリシー
Azure監視サービスは従量課金制のため、適切な設定をしないとコストが予想以上に膨らむことがあります。
監視品質を維持しながらコストを最適化することが、PjMの重要な責務です。
データ保持期間の設計
Log Analyticsのデータ保持期間は、デフォルトで30日間ですが、最大730日(2年)まで延長できます。
長期保持はコンプライアンス要件を満たす上で必要な場合もありますが、コストに直結します。
私のプロジェクトでは、データの重要度に応じて保持期間を階層化しました。
– セキュリティログ: 1年間(コンプライアンス要件)
– アプリケーションログ: 90日間(トレンド分析用)
– デバッグログ: 30日間(直近の障害調査用)
さらに、90日以上のデータはストレージアカウントへのエクスポートを設定し、必要時に検索できるようにしました。
ストレージのコストはLog Analyticsよりも大幅に安いため、長期保存が必要なログには有効な戦略です。
サンプリングとフィルタリング
Application Insightsでは、適応サンプリング機能により、トラフィックが多い場合に自動的にテレメトリデータをサンプリングします。
これにより、重要なイベント(エラーや例外)は100%保持しながら、通常のリクエストは一部のみを記録してコストを抑えられます。
私のチームでは、サンプリング率を50%に設定し、月間のApplication Insightsコストを約40%削減しました。
サンプリングしても、統計的に十分な精度でパフォーマンス分析が可能だったのです。
アラートコストの最適化
アラートルールの数と評価頻度もコストに影響します。
不要なアラートルールを削除し、評価頻度を適切に調整することで、コストを抑えられます。
私のプロジェクトでは、最初に50個以上のアラートルールを設定していましたが、実際の運用を通じて本当に必要なものは20個程度だと分かりました。
使用されていないアラートルールを削除することで、月間コストを30%削減できたのです。
判断基準として、コストとビジネスバリューのバランスを常に意識することが重要です。
すべてのログを永久保存する必要はなく、ビジネス継続性やコンプライアンスに必要な範囲で設定すれば十分です。
Kubernetes完全ガイド 第2版のようなコンテナ監視の知識も、Azure Kubernetes Service(AKS)を使用する場合には非常に役立ちます。
E2Eテスト自動化と監視を組み合わせることで、デプロイ後の品質保証をさらに強化できます。

まとめ
Azure監視・ロギング戦略は、システムの信頼性と運用効率を大きく左右する重要な要素です。
Application InsightsとLog Analyticsを適切に組み合わせることで、障害検知時間を75%短縮し、ビジネスへの影響を最小化できます。
重要なポイントは、監視対象の層ごとに適切なサービスを選択することです。
インフラメトリクスにはAzure Monitor、アプリケーションパフォーマンスにはApplication Insights、ログ分析にはLog Analyticsという基本的な使い分けを理解し、プロジェクトの規模と要件に応じてカスタマイズします。
アラート設計では、重大度に応じた通知先の階層化と、しきい値の継続的な調整が成功の鍵です。
アラート疲れを防ぎつつ、重要な障害を見逃さないバランスを取ることが求められます。
コスト最適化も忘れてはなりません。
データ保持期間の適切な設定、サンプリングの活用、不要なアラートルールの削除により、監視品質を維持しながらコストを30〜40%削減できます。
まずはApplication Insightsの自動計装から始め、実際の運用を通じて必要なカスタムテレメトリやログクエリを追加していくという段階的アプローチがおすすめです。
具体的なメトリクスとアラート履歴を記録することで、チーム全体の監視戦略を継続的に改善できます。








