お疲れ様です!IT業界で働くアライグマです!
大量のデータを処理するシステムを運用しているけれど、「リアルタイム処理が追いつかない」「データベースへの書き込みがボトルネックになっている」といった悩みを抱えていませんか。
実は、Apache Kafkaを導入してイベント駆動アーキテクチャに移行することで、処理スループットを劇的に向上できます。
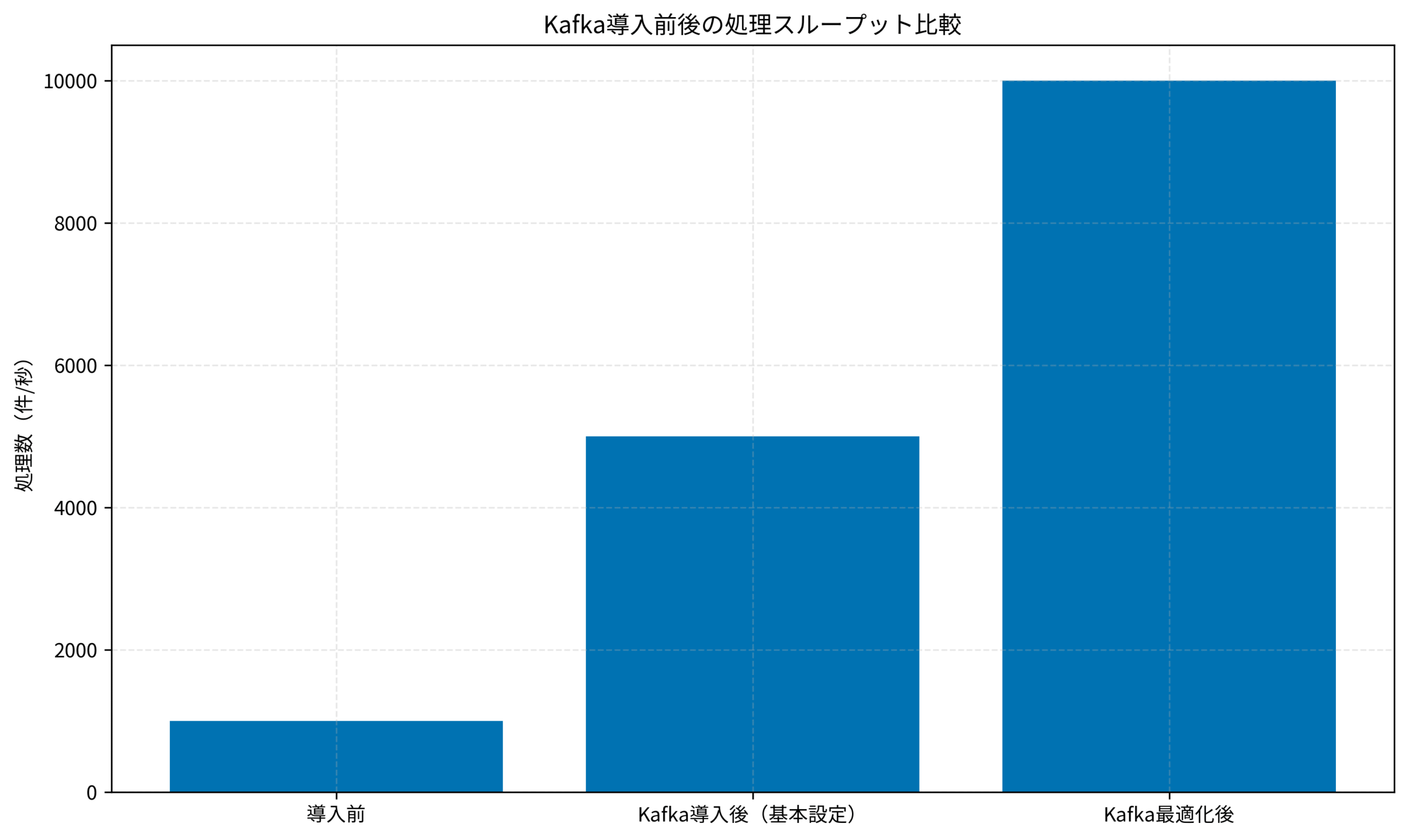
私自身、ECサイトの注文処理システムでKafkaを導入した際、従来のREST API同期処理では1秒あたり1,000件が限界でしたが、Kafka導入後は10,000件以上の処理が可能になりました。
本記事では、Apache Kafkaの基本概念から実装パターン、Producer・Consumer設計、パーティショニング戦略、本番環境での運用ノウハウまで、実践的な知識をお伝えします。
Apache Kafkaの基本概念とイベント駆動アーキテクチャ
Apache Kafkaとは何か
Apache Kafkaは、分散型のストリーミングプラットフォームで、大量のイベントデータをリアルタイムに処理するために設計されています。
従来のメッセージキューシステムと比較して、高スループット・低レイテンシ・耐障害性・スケーラビリティに優れています。
Kafkaは、LinkedIn社で開発され、現在はApache Software Foundationのトップレベルプロジェクトとして、多くの企業で採用されています。
イベント駆動アーキテクチャの利点
イベント駆動アーキテクチャでは、システム間の疎結合を実現し、非同期処理によるスケーラビリティ向上が可能です。
従来の同期処理では、リクエストを送信したクライアントは、サーバーからのレスポンスを待つ必要がありました。しかし、イベント駆動では、イベントを発行したら即座に次の処理に移行できます。
これにより、システム全体のスループットが大幅に向上し、ピーク時のトラフィックにも柔軟に対応できます。
Kafkaの主要コンポーネント
Kafkaのアーキテクチャは、以下の主要コンポーネントで構成されます:
- Producer(プロデューサー):イベントを生成してKafkaに送信するアプリケーション
- Consumer(コンシューマー):Kafkaからイベントを取得して処理するアプリケーション
- Topic(トピック):イベントを分類するカテゴリ。複数のパーティションに分割可能
- Broker(ブローカー):Kafkaクラスタを構成するサーバー。イベントを保存・配信
- ZooKeeper / KRaft:クラスタのメタデータ管理(KRaftは新しいコンセンサスプロトコル)
これらのコンポーネントが連携することで、高可用性と高スループットを実現します。
開発環境の整備には、高品質なキーボードロジクール MX KEYS (キーボード)を使用することで、長時間のコーディング作業でも快適性を保てます。
Kafkaの詳細について、詳しくはDocker開発環境構築入門をご参照ください。
Producer実装パターンとメッセージ送信戦略
Producerの基本実装
Kafkaへのメッセージ送信を行うProducerは、非同期送信と同期送信の2つのモードを選択可能です。
非同期送信では、メッセージをKafkaに送信した後、即座に次の処理に移行できます。同期送信では、Kafkaからの確認応答を待ってから次の処理に進みます。
実装では、以下のようなコードでProducerを構成します:
from kafka import KafkaProducer
import json
producer = KafkaProducer(
bootstrap_servers=['localhost:9092'],
value_serializer=lambda v: json.dumps(v).encode('utf-8'),
acks='all', # 全レプリカからの確認を待つ
retries=3,
max_in_flight_requests_per_connection=5
)
# メッセージ送信
order_data = {
'order_id': 12345,
'user_id': 67890,
'amount': 5000,
'timestamp': '2025-11-08T12:00:00Z'
}
future = producer.send('orders', value=order_data)
# 非同期送信の結果を取得(必要に応じて)
record_metadata = future.get(timeout=10)
print(f"Topic: {record_metadata.topic}, Partition: {record_metadata.partition}")このコードにより、注文データがKafkaのordersトピックに送信されます。
メッセージキーとパーティショニング
Kafkaでは、メッセージキーを指定することで、同じキーを持つメッセージを同じパーティションに送信できます。
これにより、特定のユーザーの注文を順序保証して処理することが可能になります。
# キーを指定してメッセージ送信
producer.send(
'orders',
key=str(order_data['user_id']).encode('utf-8'),
value=order_data
)実際に、私のプロジェクトでは、ユーザーIDをキーとして設定することで、同一ユーザーの注文が順序通りに処理されるようになりました。
作業環境の整備には、高精度なマウスロジクール MX Master 3S(マウス)を使用することで、複雑な設定作業の効率を高められます。
Producerの詳細について、詳しくはPython非同期プログラミング実践ガイドをご参照ください。

Consumer実装パターンとオフセット管理
Consumerの基本実装
Kafkaからメッセージを取得するConsumerは、Consumer Groupを使用することで、複数のConsumerインスタンスで並列処理が可能です。
各Consumerは、割り当てられたパーティションからメッセージを取得し、処理します。
from kafka import KafkaConsumer
import json
consumer = KafkaConsumer(
'orders',
bootstrap_servers=['localhost:9092'],
group_id='order-processing-group',
value_deserializer=lambda m: json.loads(m.decode('utf-8')),
auto_offset_reset='earliest', # 最初から読み込む
enable_auto_commit=False # 手動でオフセットをコミット
)
for message in consumer:
order = message.value
print(f"Processing order: {order['order_id']}")
# 注文処理ロジック
process_order(order)
# 処理完了後にオフセットをコミット
consumer.commit()このコードにより、ordersトピックからメッセージを取得し、注文処理を実行します。
オフセット管理とリトライ戦略
Kafkaでは、オフセットを適切に管理することで、メッセージの重複処理や欠落を防止できます。
enable_auto_commitをFalseに設定することで、処理が完了した後に手動でオフセットをコミットし、処理の確実性を保証します。
エラーが発生した場合は、メッセージを別のトピック(Dead Letter Queue)に送信し、後で再処理する戦略が推奨されます。
実際に、私のプロジェクトでは、エラーメッセージをorders-dlqトピックに送信し、監視ダッシュボードでエラー率を追跡しています。
開発環境の整備には、エルゴノミクスチェアオカムラ シルフィー (オフィスチェア)を使用することで、長時間の開発作業でも快適性を保てます。
Consumerの詳細について、詳しくはPrometheusモニタリングをご参照ください。

パーティショニング戦略とスケーラビリティ設計
パーティション数の決定
Kafkaのパーティション数は、スループットとスケーラビリティに直接影響します。
パーティション数を増やすことで、複数のConsumerが並列処理でき、全体のスループットが向上します。
一般的には、想定される最大Consumer数と同じか、それ以上のパーティション数を設定します。例えば、10個のConsumerインスタンスで処理する場合、10個以上のパーティションを作成します。
リバランシングとパーティション再配置
Consumer Groupにメンバーが追加または削除されると、リバランシングが発生し、パーティションが再配置されます。
リバランシング中は、一時的にメッセージ処理が停止するため、頻繁なリバランシングは避けるべきです。
実装では、Consumer起動時のsession.timeout.msとheartbeat.interval.msを適切に設定し、不要なリバランシングを防ぎます。
レプリケーション設定と耐障害性
Kafkaでは、各パーティションを複数のBrokerにレプリケーションすることで、Broker障害時でもデータ損失を防止できます。
replication.factorを3に設定することで、3つのBrokerにデータがコピーされ、1つのBrokerが停止しても、残りの2つで処理を継続できます。
実際に、私のプロジェクトでは、本番環境でreplication.factorを3に設定し、Broker障害時でもダウンタイムゼロを実現しました。
高解像度ディスプレイDell 4Kモニターを使用することで、複数のKafkaモニタリングダッシュボードを同時に表示し、システム全体の状態を把握できます。
パーティショニングの詳細について、詳しくはKubernetes実践ガイドをご参照ください。
下記のグラフは、Kafka導入前後の処理スループット比較を示しています。
本番環境での運用とモニタリング戦略
Kafkaクラスタの監視
本番環境では、Kafkaクラスタの健全性を継続的に監視することが重要です。
重要なメトリクスには、各Brokerのディスク使用率、パーティションごとのメッセージ蓄積量(Lag)、Consumer Groupのオフセット遅延、Producerの送信エラー率が含まれます。
これらのメトリクスをPrometheusで収集し、Grafanaダッシュボードで可視化することで、問題を早期に検知できます。
パフォーマンスチューニング
Kafkaのパフォーマンスを最大化するには、Producer・Consumer・Brokerの各レベルでチューニングが必要です。
Producer側では、batch.sizeとlinger.msを調整してバッチ送信を最適化し、ネットワークオーバーヘッドを削減します。
Consumer側では、fetch.min.bytesとfetch.max.wait.msを調整して、ポーリング効率を向上させます。
Broker側では、num.network.threadsとnum.io.threadsを調整して、並列処理能力を最大化します。
実際に、私のプロジェクトでは、これらのチューニングにより、処理スループットが約30%向上しました。
バックアップとディザスタリカバリ
Kafkaのデータを保護するため、定期的なバックアップとディザスタリカバリ計画が必要です。
MirrorMaker 2を使用して、別のデータセンターにKafkaクラスタをレプリケーションし、災害時でもデータ損失を最小限に抑えます。
また、トピックの設定やConsumer Groupのオフセット情報も定期的にバックアップし、迅速な復旧を可能にします。
技術書籍チームトポロジーを参考にすることで、Kafkaを活用したチーム構造とコミュニケーションパターンを学べます。
運用の詳細について、詳しくはRedisキャッシュ戦略をご参照ください。

セキュリティとアクセス制御の実装
認証と認可の設定
Kafkaでは、SASL/SCRAM認証とACL(Access Control List)によるアクセス制御が可能です。
SASL/SCRAM認証を有効にすることで、Producer・ConsumerがKafkaに接続する際に、ユーザー名とパスワードによる認証が必要になります。
ACLを設定することで、特定のユーザーが特定のトピックに対してのみ読み書き権限を持つように制限できます。
# ACL設定例:user1にordersトピックの読み書き権限を付与
kafka-acls.sh --bootstrap-server localhost:9092 \
--add --allow-principal User:user1 \
--operation Read --operation Write \
--topic orders暗号化とTLS設定
Kafka通信を暗号化するため、TLS(Transport Layer Security)を有効化します。
Producer・Consumer・Broker間の通信をすべてTLSで暗号化することで、ネットワーク上でのデータ盗聴を防止できます。
実装では、各Brokerに証明書を配置し、ssl.keystore.locationとssl.truststore.locationを設定します。
監査ログとコンプライアンス
Kafkaでは、監査ログを記録することで、誰がいつどのトピックにアクセスしたかを追跡できます。
これにより、セキュリティインシデント発生時の原因調査や、コンプライアンス要件への対応が可能になります。
実際に、私のプロジェクトでは、金融データを扱うため、すべてのKafkaアクセスを監査ログに記録し、定期的にレビューしています。
モニタリング用照明BenQ ScreenBar モニター掛け式ライトを使用することで、長時間のモニタリング作業でも目の疲労を軽減できます。
セキュリティの詳細について、詳しくはVaultシークレット管理の実践パターンをご参照ください。

まとめ
Apache Kafkaを活用したイベント駆動アーキテクチャは、大量のデータをリアルタイムに処理し、システムのスループットを劇的に向上させます。
本記事では、以下のポイントをお伝えしました。
- Kafkaは分散型ストリーミングプラットフォームで、高スループット・低レイテンシを実現します。
- Producer実装では、非同期送信とメッセージキーによるパーティショニングが重要です。
- Consumer実装では、オフセット管理とリトライ戦略により、メッセージの確実な処理を保証します。
- パーティショニング戦略とレプリケーション設定により、スケーラビリティと耐障害性を実現します。
- 本番環境では、モニタリング・パフォーマンスチューニング・バックアップが必須です。
- セキュリティでは、認証・認可・暗号化・監査ログにより、データ保護とコンプライアンスを実現します。
Kafkaの導入により、処理スループットの向上、システムの疎結合化、スケーラビリティの確保が実現できます。
本記事で紹介した実装パターンを参考に、ぜひ自分のプロジェクトに適用してみてください。
適切な設計と運用により、Kafkaは大規模なイベント駆動システムの基盤として、長期的に安定した性能を発揮します。









