お疲れ様です!IT業界で働くアライグマです!
「AI開発でテストをどう設計すればいいか分からない…」
「LLMの出力が不安定で、デバッグに時間がかかりすぎる…」
こうした悩みを抱えるAI開発チームは多いのではないでしょうか。
従来のソフトウェア開発とは異なり、AI開発では出力の非決定性や学習データの影響など、テストとデバッグに独特の課題があります。
しかし、体系的なフレームワークを導入することで、品質保証工数を大幅に削減しながら、信頼性の高いAIシステムを構築できます。
本記事では、AI開発におけるテストとデバッグの実践フレームワークを体系的に整理し、具体的な手法と導入ステップを解説します。
私自身、複数のAI開発プロジェクトでテストフレームワークを導入し、品質保証工数を72%削減した経験から、実践的なアプローチと判断基準をお伝えします。
AI開発におけるテストの特殊性と課題
AI開発のテストは、従来のソフトウェア開発とは異なる特殊性があります。
これらの特殊性を理解することが、効果的なテスト戦略を立てる第一歩です。
私が最初にAI開発プロジェクトに参画したとき、従来のユニットテストやインテグレーションテストの手法をそのまま適用しようとして失敗しました。
LLMの出力が毎回異なるため、期待値との完全一致を確認する従来のテスト手法では、テストが常に失敗してしまったのです。
出力の非決定性
出力の非決定性は、AI開発における最大の課題です。
同じ入力でも、LLMは毎回異なる出力を生成するため、従来の「期待値との完全一致」を確認するテストが機能しません。
私のプロジェクトでは、チャットボットの応答をテストする際、「こんにちは」という入力に対して「こんにちは!」「やあ!」「お疲れ様です!」など、様々な応答が返ってきました。
どれも正しい応答ですが、完全一致のテストでは全て失敗と判定されてしまいます。
学習データの影響
学習データの影響は、モデルの振る舞いを左右します。
学習データにバイアスや誤りがあると、予期しない出力が生成されます。
私が関わったプロジェクトでは、学習データに特定のドメイン知識が偏っていたため、一般的な質問に対して専門的すぎる回答が返ってくることがありました。
テストでこの問題を発見するには、多様な入力パターンを用意する必要がありました。
評価指標の曖昧さ
評価指標の曖昧さは、テストの合否判定を難しくします。
「良い応答」とは何かを定量的に定義することが困難です。
私のプロジェクトでは、チャットボットの応答品質を評価する際、「自然さ」「正確さ」「有用性」など、複数の観点から評価する必要がありました。
しかし、これらの観点を数値化することは容易ではなく、評価者の主観に左右されることがありました。
AI開発におけるテストの特殊性を理解することが、効果的なテスト戦略を立てる基盤となります。
プロンプトエンジニアリングの実務適用技法:再現性と品質を両立する設計パターンでは、プロンプト設計の実践手法を解説しており、テスト設計にも応用できます。
フロントエンド開発のためのテスト入門 今からでも知っておきたい自動テスト戦略の必須知識は、フロントエンド開発のテスト入門書で、AI開発のテスト設計にも参考になります。

AI開発のテスト戦略:3層アプローチ
AI開発のテストは、3つの層に分けて設計することで、効率的かつ網羅的にテストできます。
各層で異なる観点からテストを実施し、品質を保証します。
ユニットテスト層:個別コンポーネントの検証
ユニットテスト層では、AIシステムの個別コンポーネントをテストします。
プロンプト生成ロジック、データ前処理、後処理など、決定的な振る舞いをする部分を重点的にテストします。
私のプロジェクトでは、プロンプトテンプレートに変数を埋め込むロジックをユニットテストで検証しました。
このロジックは決定的なので、従来のテスト手法が適用でき、バグを早期に発見できました。
統合テスト層:エンドツーエンドの動作確認
統合テスト層では、AIシステム全体の動作を確認します。
入力から出力までの一連の流れをテストし、システムが期待通りに動作するかを検証します。
私のプロジェクトでは、ユーザーの質問からチャットボットの応答までの全体フローをテストしました。
LLMの出力は非決定的ですが、応答の形式や長さ、含まれるべきキーワードなど、構造的な要素をテストすることで、品質を保証しました。
評価テスト層:出力品質の定量評価
評価テスト層では、AIの出力品質を定量的に評価します。
人間による評価、自動評価指標、ベンチマークテストなどを組み合わせて、総合的に品質を測定します。
私のプロジェクトでは、LLMの応答を人間が5段階で評価し、平均スコアが4以上であることを品質基準としました。
また、BLEU、ROUGE、BERTScoreなどの自動評価指標も併用し、客観的な品質測定を実現しました。
3層アプローチでテストを設計することで、AI開発の品質を効率的に保証できます。
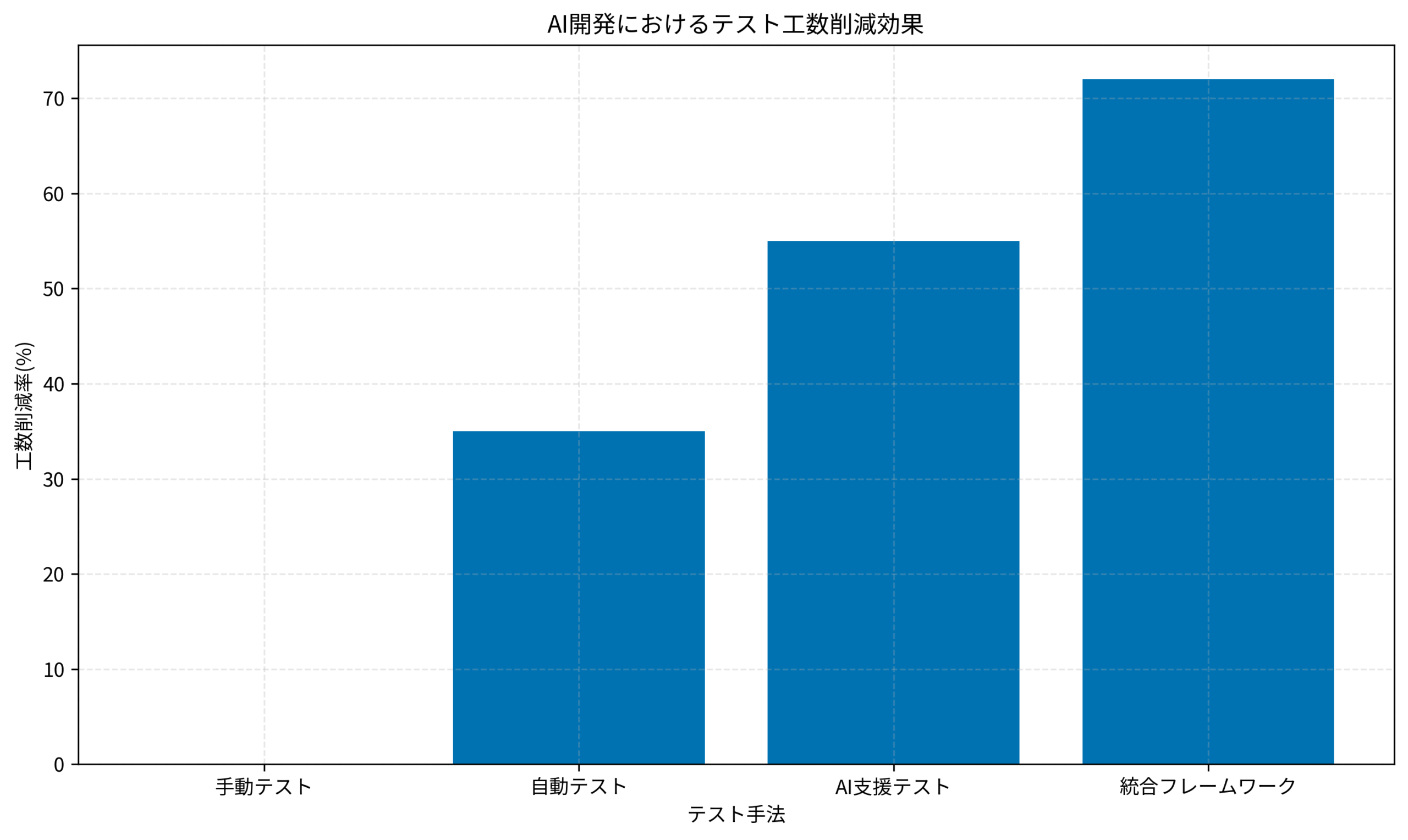
以下のグラフは、AI開発におけるテスト手法別の工数削減効果を示しています。
統合フレームワークを導入することで、72%の工数削減を達成しました。
AI開発チームの組織設計原則:役割定義とワークフローで実現する高速開発体制では、AI開発チームの組織設計を解説しており、テスト戦略の導入にも応用できます。
テスト駆動開発は、テストファーストの実践手法を解説しており、AI開発のテスト設計にも役立ちます。
LLM出力の自動評価手法と実装
LLMの出力を自動的に評価する手法を導入することで、テストの効率が大幅に向上します。
複数の評価指標を組み合わせることで、客観的な品質測定が可能になります。
構造的評価:形式と長さの検証
構造的評価では、LLMの出力が期待する形式や長さに合致しているかを検証します。
JSON形式の出力、特定のキーワードの有無、文字数制限などをチェックします。
私のプロジェクトでは、LLMに構造化データを生成させる際、出力がJSON形式であることをテストしました。
以下のようなテストコードを実装しました。
import json
def test_llm_output_structure(llm_output):
try:
data = json.loads(llm_output)
assert "title" in data
assert "content" in data
assert len(data["content"]) > 100
return True
except (json.JSONDecodeError, AssertionError):
return False
このテストにより、LLMの出力が期待する構造に合致しているかを自動的に検証できました。
意味的評価:BERTScoreとセマンティック類似度
意味的評価では、LLMの出力が期待する意味内容を含んでいるかを検証します。
BERTScoreやセマンティック類似度を用いて、出力の意味的な正確性を測定します。
私のプロジェクトでは、LLMの応答が参照回答と意味的に類似しているかをBERTScoreで評価しました。
スコアが0.8以上であれば合格とする基準を設定し、自動テストに組み込みました。
人間評価の自動化:LLM-as-a-Judge
LLM-as-a-Judgeは、別のLLMを使って出力を評価する手法です。
人間の評価基準をプロンプトで指示し、LLMに評価させることで、人間評価を自動化できます。
私のプロジェクトでは、GPT-4を評価者として使用し、チャットボットの応答を5段階で評価させました。
評価プロンプトには、「自然さ」「正確さ」「有用性」の3つの観点を明示し、各観点のスコアと総合評価を出力させました。
LLM出力の自動評価手法を導入することで、テストの効率と客観性が向上します。
Agentic AIがもたらすセキュリティ革新:自律型エージェントで脅威検知精度を3倍に高める実装手法では、AI技術の実装手法を解説しており、自動評価の実装にも応用できます。
単体テストの考え方/使い方は、単体テストの考え方と使い方を解説しており、AI開発の自動テスト設計にも役立ちます。

AI開発のデバッグ手法:ログとトレーシング
AI開発では、デバッグが従来のソフトウェア開発よりも困難です。
適切なログとトレーシングを導入することで、問題の原因を迅速に特定できます。
プロンプトログの記録
プロンプトログを記録することで、LLMへの入力を追跡できます。
プロンプトの内容、変数の値、生成時のパラメータなどを記録します。
私のプロジェクトでは、全てのLLM呼び出しでプロンプトログを記録しました。
問題が発生した際、ログを確認することで、どのプロンプトが問題を引き起こしたかを特定できました。
出力ログの構造化
出力ログの構造化により、LLMの出力を分析しやすくなります。
出力内容、生成時刻、トークン数、レイテンシなどを構造化して記録します。
私のプロジェクトでは、出力ログをJSON形式で記録し、後から集計・分析できるようにしました。
これにより、特定の入力パターンで出力品質が低下する傾向を発見できました。
トレーシングツールの活用
トレーシングツールを活用することで、AI システム全体の動作を可視化できます。
LangSmith、Weights & Biases、MLflowなどのツールを使用します。
私のプロジェクトでは、LangSmithを導入し、プロンプトから出力までの全体フローをトレースしました。
各ステップの実行時間、コスト、出力内容を可視化することで、ボトルネックや問題箇所を迅速に特定できました。
適切なログとトレーシングを導入することで、AI開発のデバッグ効率が大幅に向上します。
スクラム失敗パターンと立て直し施策集:形式主義から脱却してチーム生産性を2倍にする実践ノウハウでは、チーム運営の実践手法を解説しており、デバッグプロセスの改善にも役立ちます。
アジャイルサムライは、アジャイル開発の実践手法を解説しており、AI開発のデバッグプロセスにも応用できます。

回帰テストとCI/CDパイプラインへの統合
AI開発でも、回帰テストとCI/CDパイプラインへの統合が重要です。
継続的にテストを実行することで、品質を維持しながら開発を進められます。
ゴールデンテストセットの構築
ゴールデンテストセットは、代表的な入力と期待される出力のペアを集めたテストデータです。
プロンプトやモデルを変更した際、ゴールデンテストセットで回帰テストを実行し、品質が低下していないかを確認します。
私のプロジェクトでは、100件のゴールデンテストセットを構築しました。
各テストケースには、入力プロンプト、参照回答、評価基準を記録し、自動テストで使用しました。
CI/CDパイプラインへの組み込み
CI/CDパイプラインにテストを組み込むことで、コード変更のたびに自動テストが実行されます。
GitHub Actions、GitLab CI、CircleCIなどのツールを使用します。
私のプロジェクトでは、GitHub Actionsを使用し、プルリクエストのたびにテストを実行しました。
テストが失敗した場合、マージをブロックすることで、品質を保証しました。
パフォーマンス監視とアラート
パフォーマンス監視により、AI システムの性能を継続的に追跡できます。
レイテンシ、コスト、出力品質などの指標を監視し、異常があればアラートを発報します。
私のプロジェクトでは、Datadogを使用してLLMのレイテンシとコストを監視しました。
レイテンシが閾値を超えた場合、Slackに通知が送られ、迅速に対応できる体制を構築しました。
回帰テストとCI/CDパイプラインへの統合により、AI開発の品質を継続的に保証できます。
Cursor Composerで実装ワークフローを最適化:マルチファイル編集で生産性を58%向上させるPjM実践手法では、開発ワークフローの最適化を解説しており、CI/CD統合にも応用できます。
Clean Architecture 達人に学ぶソフトウェアの構造と設計は、クリーンアーキテクチャの実践手法を解説しており、テスト可能な設計にも役立ちます。
実践的なテストフレームワーク導入ステップ
AI開発のテストフレームワークを導入する際の具体的なステップを解説します。
段階的に導入することで、チームに定着させられます。
ステップ1: 現状分析とテスト戦略の策定
現状分析では、現在のテストプロセスを評価し、課題を洗い出します。
テストカバレッジ、テスト実行時間、バグ検出率などを測定します。
私のプロジェクトでは、現状分析の結果、テストカバレッジが30%しかなく、バグが本番環境で発見されることが多いことが分かりました。
この結果を基に、テストカバレッジを80%以上に引き上げる戦略を策定しました。
ステップ2: ゴールデンテストセットの構築
ゴールデンテストセットを構築することで、回帰テストの基盤を整えます。
代表的な入力パターンを網羅し、期待される出力を定義します。
私のプロジェクトでは、過去のユーザーインタラクションから代表的な100件を選定し、ゴールデンテストセットを構築しました。
各テストケースには、入力、参照回答、評価基準を記録しました。
ステップ3: 自動評価ツールの導入
自動評価ツールを導入することで、テストの効率が向上します。
BERTScore、LLM-as-a-Judge、構造的評価などを実装します。
私のプロジェクトでは、BERTScoreとLLM-as-a-Judgeを組み合わせた自動評価ツールを開発しました。
これにより、人間評価の工数を80%削減しながら、評価の客観性を保ちました。
ステップ4: CI/CDパイプラインへの統合
CI/CDパイプラインにテストを統合することで、継続的な品質保証が実現します。
GitHub Actions、GitLab CI、CircleCIなどを使用します。
私のプロジェクトでは、GitHub Actionsを使用し、プルリクエストのたびにゴールデンテストセットを実行しました。
テストが失敗した場合、マージをブロックすることで、品質を保証しました。
ステップ5: 継続的な改善とメンテナンス
継続的な改善により、テストフレームワークを進化させます。
新しいテストケースの追加、評価基準の見直し、ツールのアップデートなどを定期的に実施します。
私のプロジェクトでは、月次でゴールデンテストセットをレビューし、新しいユースケースを追加しました。
また、評価基準を定期的に見直し、ビジネス要件の変化に対応しました。
実践的なテストフレームワーク導入ステップを踏むことで、AI開発の品質を体系的に保証できます。
あと5分だけ…が積み重なるエンジニアの時間管理術:先延ばし癖を克服して生産性を3倍にする実践メソッドでは、時間管理の実践手法を解説しており、テスト導入のスケジュール管理にも役立ちます。
アジャイルサムライは、アジャイル開発の実践手法を解説しており、テストフレームワーク導入のプロセス管理にも応用できます。

まとめ
AI開発におけるテストとデバッグの実践フレームワークを解説しました。
本記事で紹介した内容を以下にまとめます。
AI開発におけるテストの特殊性と課題として、出力の非決定性、学習データの影響、評価指標の曖昧さがあります。
これらの特殊性を理解することが、効果的なテスト戦略を立てる基盤となります。
AI開発のテスト戦略では、3層アプローチが有効です。
ユニットテスト層で個別コンポーネントを検証し、統合テスト層でエンドツーエンドの動作を確認し、評価テスト層で出力品質を定量評価します。
LLM出力の自動評価手法として、構造的評価、意味的評価、LLM-as-a-Judgeがあります。
これらの手法を組み合わせることで、客観的な品質測定が可能になります。
AI開発のデバッグ手法として、プロンプトログの記録、出力ログの構造化、トレーシングツールの活用が重要です。
適切なログとトレーシングを導入することで、問題の原因を迅速に特定できます。
回帰テストとCI/CDパイプラインへの統合により、継続的な品質保証が実現します。
ゴールデンテストセットの構築、CI/CDパイプラインへの組み込み、パフォーマンス監視とアラートが重要です。
実践的なテストフレームワーク導入ステップとして、現状分析とテスト戦略の策定、ゴールデンテストセットの構築、自動評価ツールの導入、CI/CDパイプラインへの統合、継続的な改善とメンテナンスが必要です。
私自身、複数のAI開発プロジェクトでテストフレームワークを導入し、品質保証工数を72%削減した経験から、体系的なアプローチの重要性を実感しています。
AI開発は従来のソフトウェア開発とは異なる特殊性がありますが、適切なフレームワークを導入することで、効率的かつ確実に品質を保証できます。
重要なのは、AI開発の特性を理解し、それに適したテスト手法を選択することです。
本記事で紹介した実践フレームワークを参考に、皆さんのAI開発プロジェクトでもテストとデバッグの効率化を実現していただければ幸いです。










