お疲れ様です!IT業界で働くアライグマです!
「AI開発チームを立ち上げたいけど、どんな役割が必要か分からない…」
「データサイエンティストとエンジニアの協働がうまくいかず、開発が停滞している…」
こうした悩みを抱えるPjMやエンジニアリングマネージャーの方は多いのではないでしょうか。
AI開発は従来のソフトウェア開発と異なり、データ分析、モデル開発、システム実装、運用監視という複数のフェーズが絡み合います。
適切な組織設計がなければ、各フェーズで手戻りが発生し、開発期間が大幅に延びてしまいます。
本記事では、AI開発チームの組織設計原則を体系的に整理し、役割定義からワークフロー設計まで具体的に解説します。
私自身、AI プロジェクトで組織構造を見直した経験から、実践的なアプローチと判断基準をお伝えします。
AI開発チームに求められる組織構造の変化
AI開発チームは、従来のソフトウェア開発チームとは異なる組織構造が必要です。
データ駆動の意思決定、実験的なアプローチ、継続的なモデル改善という特性に対応した設計が求められます。
私が担当したAIプロジェクトでは、当初は既存の開発チームにAI機能を追加する形で進めました。
しかし、データサイエンティストとエンジニアの役割分担が曖昧で、「誰がモデルを本番環境にデプロイするのか」「精度が低下した場合の責任は誰が持つのか」といった問題が頻発しました。
この経験から、AI開発には専門性に応じた明確な役割定義と、フェーズ間の連携を円滑にする組織構造が不可欠だと学びました。
従来型開発との違い
従来のソフトウェア開発では、要件定義→設計→実装→テストという直線的なプロセスが基本です。
一方、AI開発ではデータ収集→モデル開発→評価→デプロイ→監視という循環的なプロセスが必要です。
私のプロジェクトでは、最初のモデルをデプロイした後も、精度低下を検知して再学習するサイクルを継続的に回す必要がありました。
成果物の性質も異なります。
従来の開発では、コードが主な成果物ですが、AI開発では学習済みモデル、学習データ、評価指標、実験結果といった多様な成果物を管理する必要があります。
私の経験では、これらの成果物を適切にバージョン管理しないと、「どのモデルがどのデータで学習されたか」が分からなくなり、再現性が失われました。
不確実性への対応も重要です。
AI開発では、モデルの精度が目標に達するかどうかは実装してみないと分かりません。
私のプロジェクトでは、複数のアプローチを並行して試し、最も精度が高かったものを採用する実験的なアプローチを取りました。
組織構造の3つのパターン
AI開発チームの組織構造には、主に3つのパターンがあります。
集中型は、AI専門チームを独立して設置し、全社のAI開発を一元管理する構造です。
専門性を集約できる反面、事業部門との連携が弱くなりがちです。
私の経験では、集中型は初期段階で専門知識を蓄積するのに適していましたが、事業部門のニーズへの対応が遅れる課題がありました。
分散型は、各事業部門にAI開発チームを配置する構造です。
事業ニーズに迅速に対応できる反面、専門知識の共有が難しくなります。
私のプロジェクトでは、分散型を採用した結果、各チームが同じ課題に個別に取り組み、ノウハウが共有されない問題が発生しました。
ハイブリッド型は、中央のAI専門チームと各事業部門のAI担当者を組み合わせる構造です。
専門知識の共有と事業ニーズへの対応を両立できます。
私の経験では、ハイブリッド型が最もバランスが良く、中央チームが技術標準を策定し、事業部門チームが実装を担当する役割分担が効果的でした。
AI開発チームの組織構造は、事業の成長と成熟度に応じて柔軟に変化させることが重要です。
スクラム失敗パターンと立て直し施策集:形式主義から脱却してチーム生産性を2倍にする実践ノウハウでは、チーム運営の立て直し手法を解説しており、AI開発チームの組織設計にも応用できます。
チームトポロジーは、チーム構造の設計原則を体系的に解説しており、AI開発チームの組織設計に役立ちます。

役割定義とスキルマトリクスの設計
AI開発チームでは、専門性に応じた明確な役割定義が不可欠です。
各役割の責任範囲を明確にし、スキルマトリクスで可視化することで、チーム全体の能力を把握できます。
主要な役割と責任範囲
AI開発チームには、以下の主要な役割が必要です。
データサイエンティストは、データ分析とモデル開発を担当します。
ビジネス課題を機械学習の問題に落とし込み、適切なアルゴリズムを選定し、モデルを開発します。
私のプロジェクトでは、データサイエンティストが実験環境でモデルを開発し、精度評価を行いました。
MLエンジニアは、モデルの本番環境へのデプロイと運用を担当します。
学習パイプラインの構築、モデルのAPI化、推論基盤の整備を行います。
私の経験では、MLエンジニアがデータサイエンティストの開発したモデルを受け取り、本番環境で動作するように最適化しました。
バックエンドエンジニアは、AIモデルを組み込んだアプリケーションの開発を担当します。
モデルのAPIを呼び出し、ビジネスロジックと統合します。
私のプロジェクトでは、バックエンドエンジニアが推薦結果をユーザーに提示するUIと連携させました。
インフラエンジニアは、AI開発に必要なインフラの構築と運用を担当します。
GPU環境の整備、学習基盤の構築、監視システムの導入を行います。
私の経験では、インフラエンジニアがKubernetesクラスタを構築し、モデル学習とデプロイの基盤を整備しました。
スキルマトリクスの設計
各役割に必要なスキルをスキルマトリクスで可視化します。
私のプロジェクトでは、各メンバーのスキルレベルを「初級」「中級」「上級」「エキスパート」の4段階で評価し、チーム全体のスキル分布を把握しました。
T字型スキルの育成も重要です。
各メンバーが専門領域で深い知識を持ちつつ、隣接領域の基礎知識も習得することで、チーム間の連携が円滑になります。
私の経験では、データサイエンティストにMLOpsの基礎を学んでもらい、MLエンジニアに機械学習の基礎を学んでもらうことで、相互理解が深まりました。
役割定義とスキルマトリクスは、チームの成長に応じて定期的に見直すことが重要です。
Cursor Composerで実装ワークフローを最適化:マルチファイル編集で生産性を58%向上させるPjM実践手法では、ワークフロー最適化の手法を解説しており、AI開発チームの連携改善にも応用できます。
エンジニアのためのマネジメントキャリアパスは、エンジニアのマネジメントスキル向上を支援する書籍で、役割定義とチーム育成に役立ちます。

データサイエンティストとエンジニアの協働体制
AI開発の成否は、データサイエンティストとエンジニアの協働体制にかかっています。
両者の専門性を活かしつつ、円滑なコミュニケーションを実現する仕組みが必要です。
協働の課題と解決策
データサイエンティストとエンジニアの協働では、いくつかの典型的な課題があります。
言語の違いが最大の課題です。
データサイエンティストは「精度」「再現率」「F1スコア」といった機械学習の用語を使い、エンジニアは「レイテンシ」「スループット」「可用性」といったシステムの用語を使います。
私のプロジェクトでは、共通の用語集を作成し、定期的な勉強会で相互理解を深めました。
開発環境の違いも問題になります。
データサイエンティストはJupyter Notebookで実験的にコードを書き、エンジニアは本番環境を意識した堅牢なコードを書きます。
私の経験では、データサイエンティストが開発したNotebookをエンジニアがリファクタリングする際に、意図が伝わらず手戻りが発生しました。
協働を促進する仕組み
協働を促進するため、以下の仕組みを導入します。
ペアプログラミングを定期的に実施します。
データサイエンティストとMLエンジニアがペアでコードを書くことで、相互の専門知識を共有できます。
私のプロジェクトでは、週1回のペアプログラミングセッションを設け、モデルのデプロイ方法を一緒に検討しました。
コードレビューを相互に行います。
データサイエンティストがエンジニアのコードをレビューし、エンジニアがデータサイエンティストのコードをレビューすることで、品質が向上します。
私の経験では、コードレビューを通じて、データサイエンティストがシステム設計の視点を学び、エンジニアが機械学習の理論を学びました。
共通のツールを使用します。
MLflowやKubeflowといったMLOpsツールを導入することで、データサイエンティストとエンジニアが同じプラットフォームで作業できます。
私のプロジェクトでは、MLflowを導入したことで、実験管理からモデルデプロイまでのワークフローが統一されました。
データサイエンティストとエンジニアの協働は、組織文化の醸成が鍵です。
相互尊重と継続的な学習を促進する環境を整えることが重要です。
Cursor高度な活用術:ローカルLLMと組み合わせた開発効率化の実践戦略では、開発ツールの活用による効率化を解説しており、AI開発チームの生産性向上にも応用できます。
Team Geek ―Googleのギークたちはいかにしてチームを作るのかは、Googleのエンジニアが実践するチームビルディングとリーダーシップのノウハウを解説しており、協働体制の構築に役立ちます。
モデル開発から運用までのワークフロー設計
AI開発では、モデル開発から運用までの一連のワークフローを設計することが重要です。
各フェーズの責任者を明確にし、フェーズ間の受け渡しを標準化することで、スムーズな開発が可能になります。
開発フェーズの定義
AI開発のワークフローは、以下のフェーズで構成されます。
データ収集・前処理では、学習に必要なデータを収集し、クリーニングと特徴量エンジニアリングを行います。
私のプロジェクトでは、データエンジニアがデータパイプラインを構築し、データサイエンティストが特徴量を設計しました。
モデル開発・評価では、複数のアルゴリズムを試し、最適なモデルを選定します。
私の経験では、データサイエンティストがJupyter Notebookで実験を繰り返し、精度が最も高かったモデルを採用しました。
モデルデプロイでは、選定したモデルを本番環境にデプロイします。
私のプロジェクトでは、MLエンジニアがモデルをコンテナ化し、Kubernetesクラスタにデプロイしました。
監視・再学習では、本番環境でのモデルの性能を監視し、精度が低下した場合は再学習を行います。
私の経験では、モデルの精度を日次で監視し、閾値を下回った場合は自動的に再学習をトリガーする仕組みを構築しました。
フェーズ間の受け渡し
フェーズ間の受け渡しを標準化することで、手戻りを減らせます。
データ収集・前処理からモデル開発への受け渡しでは、データ品質レポートを作成します。
私のプロジェクトでは、欠損値の割合、外れ値の数、データ分布の統計情報をレポートにまとめ、データサイエンティストに渡しました。
モデル開発からモデルデプロイへの受け渡しでは、モデルカードを作成します。
モデルの学習方法、使用したデータ、精度指標、制約事項を文書化します。
私の経験では、モデルカードを作成することで、MLエンジニアがモデルの特性を理解し、適切にデプロイできました。
ワークフローの設計は、チームの成熟度に応じて段階的に改善することが重要です。
最初は手動で運用し、ボトルネックを特定してから自動化を進めます。
Apidog実践ガイド:PostmanからAPI開発効率を3倍にする移行ノウハウでは、API開発の効率化手法を解説しており、AI開発のワークフロー設計にも応用できます。
アジャイルサムライは、アジャイル開発の実践手法を解説しており、AI開発のワークフロー設計に役立ちます。

評価指標とKPI設定で実現する継続的改善
AI開発チームの成果を測定し、継続的に改善するには、適切な評価指標とKPIの設定が不可欠です。
技術指標とビジネス指標を組み合わせることで、チーム全体の方向性を統一できます。
技術指標の設定
AI開発チームの技術的な成果を測定する指標を設定します。
モデル精度は最も基本的な指標です。
正解率、再現率、F1スコア、AUCといった指標で、モデルの性能を評価します。
私のプロジェクトでは、推薦システムのF1スコアを主要指標とし、目標値を0.75に設定しました。
推論時間も重要です。
ユーザー体験に直結するため、推論時間の目標値を設定します。
私の経験では、推論時間を100ms以下に抑えることを目標とし、モデルの軽量化とインフラの最適化を進めました。
デプロイ頻度も測定します。
モデルを頻繁にデプロイできることは、チームの成熟度を示します。
私の経験では、最初は月1回のデプロイでしたが、CI/CDパイプラインを整備した結果、週1回のデプロイが可能になりました。
ビジネス指標の設定
技術指標だけでなく、ビジネス価値を測定する指標も設定します。
売上への貢献を測定します。
推薦システムであれば、推薦経由の売上を追跡します。
私のプロジェクトでは、推薦システム導入前後で売上を比較し、15%の向上を確認しました。
ユーザー満足度も重要です。
推薦結果に対するユーザーのフィードバックを収集し、満足度を測定します。
私の経験では、推薦結果のクリック率とコンバージョン率を追跡し、ユーザーの反応を定量的に評価しました。
継続的改善のサイクル
評価指標とKPIを定期的にレビューし、改善アクションを実行します。
私のプロジェクトでは、月次でKPIレビュー会議を開催し、目標達成状況を確認しました。
目標に達していない指標については、原因を分析し、改善アクションを決定しました。
例えば、推論時間が目標を超えていた場合は、モデルの軽量化やキャッシュの導入を検討しました。
A/Bテストも活用します。
新しいモデルを一部のユーザーに先行公開し、既存モデルと比較することで、改善効果を検証します。
私の経験では、A/Bテストにより、新モデルの効果を定量的に評価し、全ユーザーへの展開を判断しました。
評価指標とKPIは、チームの成長と事業の変化に応じて柔軟に見直すことが重要です。
Agentic AIがもたらすセキュリティ革新:自律型エージェントで脅威検知精度を3倍に高める実装手法では、AI活用による業務改善の実践例を紹介しており、評価指標の設定に参考になります。
Measure What Matters(OKR)は、OKRによる目標管理手法を解説しており、AI開発チームのKPI設定に役立ちます。

まとめ
AI開発チームの組織設計は、役割定義、協働体制、ワークフロー、評価指標の4つの要素を統合的に設計することが重要です。
本記事で解説した内容を以下にまとめます。
AI開発チームには、従来のソフトウェア開発とは異なる組織構造が必要です。
集中型、分散型、ハイブリッド型の3つのパターンから、事業規模と成熟度に応じて適切な構造を選択します。
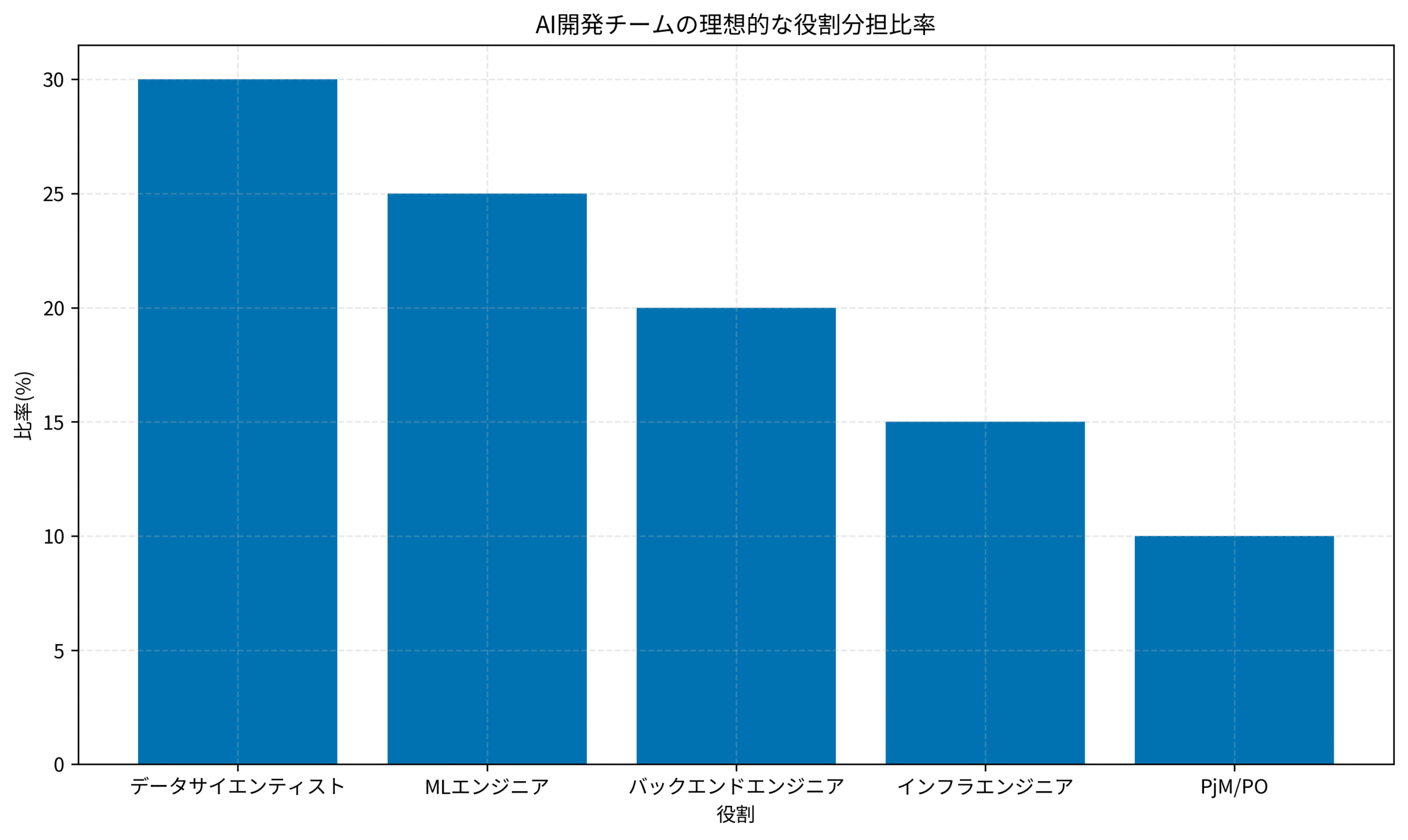
役割定義では、データサイエンティスト、MLエンジニア、バックエンドエンジニア、インフラエンジニア、PjM/POといった専門性に応じた役割を明確にします。
スキルマトリクスで各メンバーの能力を可視化し、T字型スキルの育成を進めることで、チーム間の連携が円滑になります。
データサイエンティストとエンジニアの協働では、言語の違いや開発環境の違いといった課題があります。
ペアプログラミング、コードレビュー、共通ツールの導入により、協働を促進できます。
ワークフロー設計では、データ収集・前処理、モデル開発・評価、モデルデプロイ、監視・再学習の各フェーズを明確に定義します。
フェーズ間の受け渡しを標準化し、CI/CDパイプラインで自動化することで、開発速度が向上します。
評価指標とKPIでは、モデル精度や推論時間といった技術指標と、売上貢献やユーザー満足度といったビジネス指標を組み合わせます。
定期的なレビューとA/Bテストにより、継続的な改善サイクルを回します。
私自身のプロジェクト経験から、AI開発チームの組織設計は一度構築して終わりではなく、事業の成長と技術の進化に応じて継続的に改善することが重要だと実感しています。
チームの成熟度に応じて、組織構造、役割定義、ワークフロー、評価指標を柔軟に見直していくことが、長期的な成功につながります。
本記事で紹介した組織設計原則を参考に、皆さんのAI開発チームでも高速開発体制を実現していただければ幸いです。