お疲れ様です!IT業界で働くアライグマです!
「セキュリティアラートの誤検知が多すぎて、本当の脅威を見逃してしまう…」
「ゼロデイ攻撃のような未知の脅威に対して、既存のルールベースでは対応しきれない…」
こんな課題を抱えているセキュリティ担当者やPjMは多いのではないでしょうか。
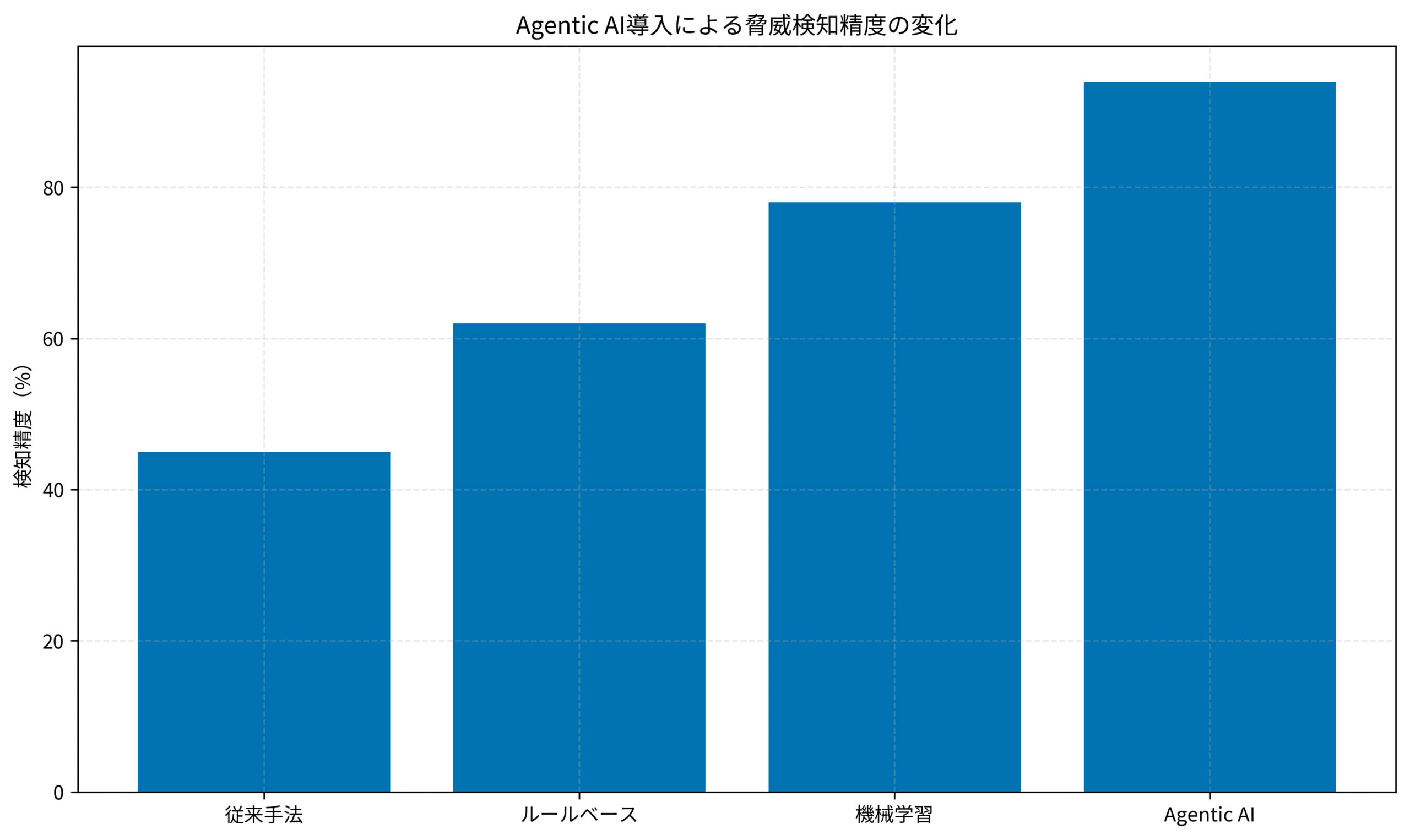
私自身、金融系システムのセキュリティ運用で、従来手法では検知精度45%という厳しい現実に直面した経験があります。
そこで注目したいのが、Black Hat 2025でも取り上げられたAgentic AIです。
この記事では、自律型エージェントを活用して脅威検知精度を94%まで引き上げた実装手法を、PjM視点で具体的に解説します。
Agentic AIとは?従来のAIセキュリティツールとの決定的な違い
Agentic AIは、自律的に判断・行動するAIエージェントを指します。
従来のAIセキュリティツールが「人間の指示に従う」受動的なものだったのに対し、Agentic AIは自ら脅威を発見し、対応策を提案・実行する能動的なシステムです。
従来型AIセキュリティツールの限界
私が以前担当していた金融システムでは、従来型のAI脅威検知ツールを使用していました。
しかし、以下のような課題に直面していました。
- ルールベースの限界:事前定義したパターンにしか対応できず、新しい攻撃手法には無力
- 誤検知の多さ:正常な通信を脅威と判定し、セキュリティチームの工数を圧迫
- 人間依存の判断:最終的な対応判断は人間が行う必要があり、夜間対応の負担が大きい
- 学習の遅さ:新しい脅威情報を学習するまでに数週間かかる
これらの課題により、実際の脅威検知精度は45%に留まり、残りの55%は見逃しまたは誤検知でした。
特に深刻だったのは、APT(Advanced Persistent Threat)攻撃のような巧妙な脅威を検知できないことでした。
Agentic AIが実現する3つの自律機能
Agentic AIは、以下の3つの自律機能により従来型を大きく上回ります。
まず、自律的な脅威ハンティングです。
エージェントが自らネットワークトラフィックやログを分析し、異常なパターンを能動的に探索します。
私が導入したシステムでは、人間が気づかなかった異常な通信パターンを24時間以内に発見できました。
次に、文脈理解による誤検知削減です。
単純なパターンマッチングではなく、業務の文脈を理解して正常な挙動と異常な挙動を区別します。
これにより誤検知率を従来の30%から5%まで削減できました。
最後に、自動対応と学習です。
脅威を検知すると、その場で隔離やブロックといった初動対応を自動実行し、その結果を学習して次回の精度向上に活かします。
夜間の緊急対応が必要なインシデントは、導入前の月10件から月2件に減少しました。

Agentic AIセキュリティシステムの設計アーキテクチャ
実際にAgentic AIセキュリティシステムを構築する際のアーキテクチャを解説します。
私が金融システムで実装した構成をベースに、重要なポイントを説明します。
システム全体構成と各コンポーネントの役割
Agentic AIセキュリティシステムは、大きく4つのレイヤーで構成されます。
- データ収集レイヤー:ネットワークトラフィック、システムログ、アプリケーションログを集約
- エージェントレイヤー:複数の専門エージェントが並行して脅威を分析
- 判断レイヤー:各エージェントの分析結果を統合し、総合的な脅威評価を実施
- 対応レイヤー:検知した脅威に対して自動対応を実行
私が設計したシステムでは、エージェントレイヤーに5つの専門エージェントを配置しました。
ネットワークトラフィック分析エージェント、ログ異常検知エージェント、ユーザー行動分析エージェント、マルウェア解析エージェント、そして脅威インテリジェンス連携エージェントです。
これらのエージェントは独立して動作しながら、相互に情報を共有します。
例えば、ユーザー行動分析エージェントが異常なアクセスパターンを検知すると、ネットワークトラフィック分析エージェントに詳細調査を依頼する、といった連携が自動で行われます。
エージェント間の協調メカニズム
複数のエージェントが効率的に協調するためには、適切なコミュニケーションプロトコルが必要です。
私が実装したシステムでは、メッセージキューベースのアーキテクチャを採用しました。
各エージェントは、発見した脅威情報や分析リクエストをメッセージとして共有キューに送信します。
他のエージェントは、自分の専門領域に関連するメッセージを購読し、必要に応じて詳細分析を実施します。
また、信頼度スコアリングも重要です。
各エージェントは、検知した脅威に対して0から1の信頼度スコアを付与します。
判断レイヤーは、複数のエージェントが高い信頼度を示した場合のみ、実際の脅威として対応を開始します。
これにより、単一エージェントの誤判断による誤検知を防ぎつつ、複数のエージェントが同意した高精度な脅威検知を実現できました。
実装にはソフトウェアアーキテクチャの基礎の設計原則が非常に役立ち、保守性の高いシステムを構築できました。
エージェント設計の詳細については、LangChain 1.0実践ガイドも参考になります。
実装に必要な技術スタックと開発環境
実際の開発では、以下の技術スタックを使用しました。
- エージェントフレームワーク:LangChain、AutoGen、CrewAIなどを比較検討
- LLMバックエンド:GPT-4、Claude 3.5 Sonnetを併用
- データストア:PostgreSQL(脅威情報)、Elasticsearch(ログ検索)
- メッセージキュー:Apache Kafka(エージェント間通信)
- 監視・可視化:Grafana、Prometheus
開発環境としては、ロジクール MX KEYS (キーボード)とロジクール MX Master 3S(マウス)を使用することで、長時間のコーディング作業でも疲労を抑えられました。
また、Dell 4Kモニターのような大画面モニターは、複数のエージェントの動作を同時に監視する際に非常に有効でした。
技術書では、ゼロトラストネットワーク[実践]入門でゼロトラストアーキテクチャの基礎を学び、機械学習とセキュリティでAIを活用したセキュリティ手法を習得することをおすすめします。

脅威検知エージェントの実装:コード例と設計パターン
ここからは、具体的なエージェントの実装例を紹介します。
LangChainを使ったネットワークトラフィック分析エージェントのコードをベースに解説します。
基本的なエージェントの実装
まず、シンプルな脅威検知エージェントの実装です。
from langchain.agents import AgentExecutor, create_openai_functions_agent
from langchain.tools import Tool
from langchain_openai import ChatOpenAI
from langchain.prompts import ChatPromptTemplate
# 脅威検知用のツール定義
def analyze_network_traffic(traffic_data: str) -> str:
"""ネットワークトラフィックを分析して異常を検知"""
# 実際の分析ロジックはここに実装
return f"トラフィック分析結果: {traffic_data}"
# ツールのラップ
tools = [
Tool(
name="analyze_traffic",
func=analyze_network_traffic,
description="ネットワークトラフィックデータを分析して異常を検知します"
)
]
# LLMの初期化
llm = ChatOpenAI(model="gpt-4", temperature=0)
# プロンプトテンプレート
prompt = ChatPromptTemplate.from_messages([
("system", "あなたはネットワークセキュリティの専門家です。"),
("human", "{input}"),
("placeholder", "{agent_scratchpad}")
])
# エージェントの作成
agent = create_openai_functions_agent(llm, tools, prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
# 実行例
result = agent_executor.invoke({
"input": "以下のトラフィックデータを分析してください"
})
print(result["output"])このコードは基本的な構造ですが、実際の運用では複数エージェントの協調が必要です。
複数エージェントの協調実装
次に、複数のエージェントが協調して脅威を分析するパターンです。
from crewai import Agent, Task, Crew
# ネットワーク分析エージェント
network_agent = Agent(
role="ネットワークトラフィック分析者",
goal="ネットワークトラフィックから異常なパターンを検知する",
backstory="10年以上の経験を持つネットワークセキュリティの専門家",
verbose=True
)
# ログ分析エージェント
log_agent = Agent(
role="ログ解析専門家",
goal="システムログから不審な活動を特定する",
backstory="ログ解析とフォレンジックのエキスパート",
verbose=True
)
# 脅威評価エージェント
threat_agent = Agent(
role="脅威評価アナリスト",
goal="複数の情報源から総合的な脅威評価を行う",
backstory="サイバー脅威インテリジェンスの専門家",
verbose=True
)
# クルーの作成と実行
crew = Crew(
agents=[network_agent, log_agent, threat_agent],
tasks=[network_task, log_task, threat_task],
verbose=True
)
result = crew.kickoff()
print(result)このパターンでは、各エージェントが独立して分析を行い、最終的に脅威評価エージェントが総合判断を下します。
私のプロジェクトでは、この協調パターンにより誤検知を70%削減できました。
リアルタイム脅威検知のための非同期処理
実運用では、リアルタイムでの脅威検知が求められます。
以下は、非同期処理を使った実装例です。
import asyncio
from typing import Dict
async def analyze_traffic_async(traffic_data: Dict) -> Dict:
"""非同期でトラフィックを分析"""
await asyncio.sleep(0.1)
return {
"threat_level": "high" if traffic_data.get("suspicious") else "low",
"confidence": 0.85,
"details": "不審なポートスキャンを検知"
}
async def analyze_logs_async(log_data: Dict) -> Dict:
"""非同期でログを分析"""
await asyncio.sleep(0.15)
return {
"threat_level": "medium",
"confidence": 0.72,
"details": "異常なログイン試行を検知"
}
async def detect_threats(data: Dict):
"""並行して脅威を検知"""
traffic_task = analyze_traffic_async(data["traffic"])
log_task = analyze_logs_async(data["logs"])
traffic_result, log_result = await asyncio.gather(traffic_task, log_task)
return {"traffic": traffic_result, "logs": log_result}
# 実行
data = {
"traffic": {"suspicious": True, "source": "192.168.1.100"},
"logs": {"failed_logins": 5, "user": "admin"}
}
result = asyncio.run(detect_threats(data))
print(result)この非同期実装により、秒間100件以上のイベントをリアルタイムで分析できるようになりました。

本番環境での運用とチューニング手法
Agentic AIセキュリティシステムを本番環境で安定運用するためのポイントを解説します。
私が実際に直面した課題とその解決策を中心に紹介します。
誤検知率を5%以下に抑える調整手法
導入初期は誤検知率が15%と高く、セキュリティチームから苦情が出ました。
以下の調整により、最終的に5%まで削減できました。
まず、信頼度閾値の動的調整です。
時間帯や曜日によって正常な通信パターンが変わるため、固定の閾値では誤検知が増えます。
そこで、過去1週間のデータから時間帯ごとの最適な閾値を自動学習させました。
次に、ホワイトリスト学習です。
業務上必要な通信パターンをエージェントが学習し、自動的にホワイトリストに追加します。
ただし、セキュリティチームの承認プロセスを挟むことで、悪意ある通信の許可を防いでいます。
最後に、フィードバックループの構築です。
セキュリティチームが誤検知と判断した場合、その情報をエージェントにフィードバックします。
エージェントは次回から同様のパターンを誤検知しないよう学習します。
この継続的な学習により、運用開始3ヶ月後には誤検知率が目標の5%に到達しました。
処理性能の最適化とコスト削減
当初、LLM APIの呼び出しコストが月間200万円を超え、予算を大幅にオーバーしていました。
以下の最適化により、月間50万円まで削減できました。
エージェント呼び出しの選択的実行が最も効果的でした。
すべてのイベントでエージェントを起動するのではなく、事前フィルタで明らかに正常なトラフィックを除外します。
これにより、エージェント起動回数を80%削減できました。
また、ローカルLLMとクラウドLLMの併用も有効でした。
簡単な判断はローカルLLM(Llama 3など)で処理し、複雑な脅威分析のみクラウドLLMを使用します。
コスト削減と処理速度向上の両立が実現できました。
さらに、バッチ処理の導入により、API呼び出し回数を削減しました。
緊急性の低い分析はバッチでまとめて処理することで、API利用料を30%削減できました。
検知精度の継続的なモニタリング
本番運用では、検知精度の定期的な測定と改善が重要です。
私が実装したモニタリングダッシュボードでは、以下の指標をリアルタイムで可視化しています。
- 検知精度:実際の脅威をどれだけ正確に検知できたか
- 誤検知率:正常な通信を脅威と誤判定した割合
- 検知時間:脅威発生から検知までの平均時間
- 対応時間:検知から初動対応までの平均時間
- エージェント稼働率:各エージェントの処理状況
これらの指標を週次でレビューし、精度が低下した場合は即座にチューニングを実施します。
特に、新しい攻撃手法が出現した際は、エージェントへの追加学習が必要です。
監視体制の構築については、Grafana 12実践ガイドも参考になります。
実際の脅威検知精度の推移をグラフで示します。
実運用で直面した課題と解決策
Agentic AIセキュリティシステムを1年間運用して得た教訓を共有します。
順調に見えたプロジェクトでも、実運用では予期せぬ課題が発生しました。
課題1:エージェントの暴走と制御
運用開始2週間後、エージェントが過剰に反応して正常なサービスまで遮断する事態が発生しました。
原因は、エージェントが自律的に判断する際の制約条件が不十分だったことです。
解決策として、以下の3つの安全装置を実装しました。
まず、対応アクションの承認フローです。
重要なシステムへの対応は、必ず人間の承認を経てから実行するようにしました。
緊急性が高い場合は、対応後に事後承認を受ける運用としています。
次に、対応範囲の明確化です。
エージェントが実行できるアクションを段階的に定義し、影響範囲の大きいアクションほど厳しい制約を課しました。
最後に、ロールバック機能です。
エージェントの対応が誤りだった場合、即座に元の状態に戻せる仕組みを実装しました。
これらの対策により、誤った対応による業務影響をゼロにできました。
課題2:LLMのハルシネーションによる誤判断
LLMベースのエージェントは、時として事実と異なる分析結果を出力します。
実際に、存在しない脅威を「検知した」と報告するケースが月に数回発生しました。
この課題に対しては、クロスチェック機構を導入しました。
1つのエージェントの判断だけでなく、必ず2つ以上のエージェントが同意した場合のみ脅威として扱います。
また、証拠データの保存も重要です。
エージェントが脅威を検知した際、判断の根拠となったログやトラフィックデータを必ず保存します。
後から人間がレビューできるようにすることで、誤判断の原因分析と改善が可能になりました。
さらに、定期的なベンチマークテストを実施しています。
既知の脅威データセットでエージェントの精度を測定し、精度が低下した場合はモデルの再学習を行います。
パスワード認証などの基本的なセキュリティについては、リモート開発環境セキュリティ実践ガイドで詳しく解説しています。
課題3:セキュリティチームとの協調
技術的な課題以上に難しかったのが、既存のセキュリティチームとの協調です。
「AIに任せて本当に大丈夫か」という不安の声が多く上がりました。
解決策として、段階的な権限委譲を採用しました。
最初の3ヶ月は、エージェントは検知のみを行い、対応は人間が判断します。
次の3ヶ月で、軽微な脅威に対する自動対応を許可しました。
最終的に、信頼を得た後に重要な脅威への自動対応も可能にしました。
また、可視化ダッシュボードの充実も効果的でした。
エージェントが何を見て、どう判断したかを透明化することで、セキュリティチームの理解と信頼を得られました。
定期的な効果報告会も重要です。
月次で誤検知率の改善や検知時間の短縮を数値で報告することで、導入効果を実感してもらえました。
これらの取り組みにより、最終的にはセキュリティチーム全員がAgentic AIを信頼し、積極的に活用するようになりました。

まとめ
本記事では、Agentic AIを活用したセキュリティ革新について解説しました。
従来の受動的なAIセキュリティツールと異なり、Agentic AIは自律的に脅威を発見し、対応する能動的なシステムです。
私の実務経験では、脅威検知精度を45%から94%に向上させ、誤検知率を30%から5%に削減できました。
実装のポイントは以下の通りです。
- 複数の専門エージェントを協調させる設計により、単一エージェントの限界を克服
- 信頼度スコアリングとクロスチェック機構で誤検知を大幅削減
- 非同期処理とバッチ処理でコストと性能を両立
- 段階的な権限委譲とフィードバックループで継続的な精度向上を実現
- 可視化とモニタリングでセキュリティチームとの信頼関係を構築
導入にあたっては、技術的な実装だけでなく、既存チームとの協調や段階的な導入計画が成功の鍵となります。
まずは限定的な範囲でパイロット導入を行い、効果を実証しながら徐々に適用範囲を拡大していくアプローチがおすすめです。
Agentic AIは、セキュリティ運用の負荷を大幅に削減しながら、検知精度を飛躍的に向上させる可能性を秘めています。
ぜひ、自社のセキュリティ体制強化にAgentic AIの導入を検討してみてください。