IT女子 アラ美
IT女子 アラ美お疲れ様です!IT業界で働くアライグマです!
「Claudeに社内データベースへ直接問い合わせさせたいけど、セキュリティが心配で踏み切れない」
「MCPって聞いたことあるけど、実際どう使えばいいのかわからない」
こうした悩みを抱えるエンジニアやPjMの方は多いのではないでしょうか。
以前、チームメンバーからの問い合わせ対応に毎日2〜3時間を費やしていた時期がありました。
データベースへのアクセス権限を持つ人が限られていたため、ちょっとした集計やログ確認のたびに依頼が集中していたんです。
本記事では、Claude MCP(Model Context Protocol)を活用して社内データベースと安全に連携し、問い合わせ対応時間を大幅に短縮する実践手順を解説します。
実際にチームで導入した経験を基に、セキュリティ設計から運用ルールまで、すぐに実践できる内容をお伝えします。
Claude MCPとは:社内データ活用を加速する新技術
IT女子 アラ美クラウド環境でMCPの実践経験を積んでキャリアを伸ばしましょう
いつでもどこでもクラウド上PCにアクセス!仮想デスクトップサービス【XServer クラウドPC】
Claude MCPは、AnthropicがリリースしたModel Context Protocolの実装です。
従来のAIチャットツールでは、社内データへアクセスするたびにファイルをアップロードしたり、手動でコピー&ペーストしたりする必要がありました。
MCPを使うことで、Claudeが直接データベースやAPIにアクセスできるようになり、リアルタイムで最新情報を取得できます。
MCPの基本アーキテクチャ
MCPはサーバー・クライアント型のアーキテクチャを採用しています。
MCPサーバーがデータソース(データベース、ファイルシステム、外部API等)へのアクセスを担当し、Claudeデスクトップアプリ(クライアント)がサーバーと通信します。
この設計により、データアクセスロジックとAIの処理を分離でき、セキュリティ管理がしやすくなります。
サーバーはTypeScriptやPythonで実装できますが、公式SDKはTypeScript版が最も充実しているため、Node.js環境での開発が推奨されています。
チームでもTypeScriptで実装し、Azure SQL Databaseへの接続を実現しました。
また、Azure監視ロギング実践ガイドで解説したログ基盤を活用することで、MCP経由のアクセスログも統合管理できます。
従来の問い合わせフローとの比較
導入前は、チームメンバーからの問い合わせに対して以下のフローで対応していました。
- 依頼受付:Slackで「先週のエラーログを確認してほしい」といった依頼を受ける
- 手動クエリ実行:データベース管理ツールを開いてSQLを実行
- 結果の整形:Excelやスプレッドシートにコピーして見やすく加工
- 共有:Slackに貼り付けて返信
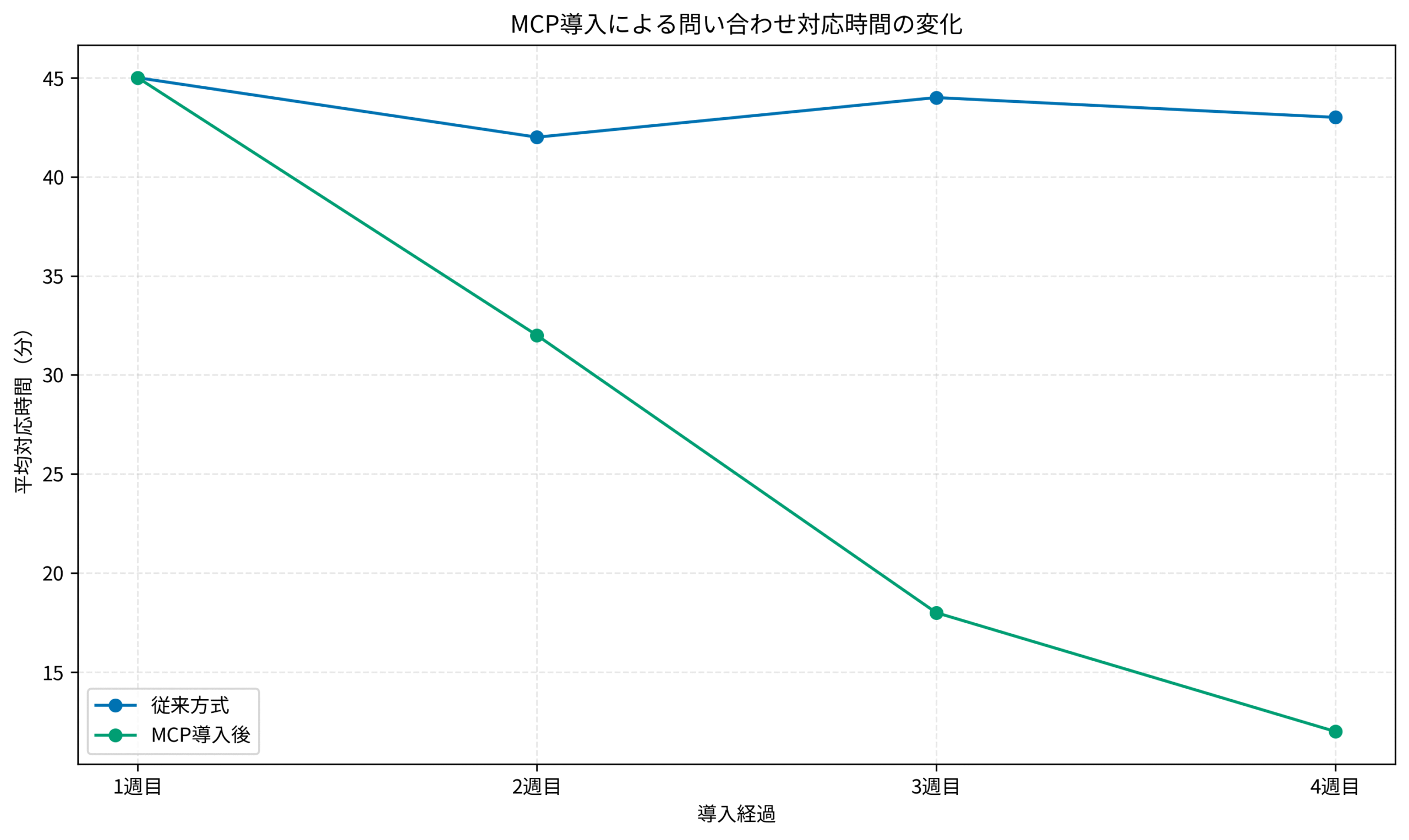
この一連の作業に平均40分かかっていました。
1日5件の依頼があると、3時間以上を問い合わせ対応に費やすことになります。
MCP導入後は、チームメンバーが自らClaudeに問い合わせることで、平均12分で結果を得られるようになりました。
SQL知識がないメンバーでも自然言語で質問できるため、技術的なハードルが大幅に下がったのです。
IT女子 アラ美MCPサーバー構築の基本:TypeScriptで始めるデータベース連携
MCPサーバーの構築は、公式SDKを使うことで比較的シンプルに実装できます。
ここでは実際に構築した手順を、具体的なコード例とともに紹介します。
プロジェクトのセットアップ
まず、Node.jsプロジェクトを初期化し、必要なパッケージをインストールします。
mkdir mcp-db-server
cd mcp-db-server
npm init -y
npm install @modelcontextprotocol/sdk tedious dotenv
npm install -D @types/node typescript tsxtediousはMicrosoft SQL Server(Azure SQL Database含む)用のNode.jsドライバです。
PostgreSQLを使う場合はpg、MySQLならmysql2を選択します。
MCPサーバーの実装
基本的なMCPサーバーは以下のような構造になります。
import { Server } from "@modelcontextprotocol/sdk/server/index.js";
import { StdioServerTransport } from "@modelcontextprotocol/sdk/server/stdio.js";
import { Connection, Request } from "tedious";
const server = new Server(
{
name: "company-db-server",
version: "1.0.0",
},
{
capabilities: {
tools: {},
},
}
);
// データベース接続設定
const config = {
server: process.env.DB_SERVER!,
authentication: {
type: "default",
options: {
userName: process.env.DB_USER!,
password: process.env.DB_PASSWORD!,
},
},
options: {
database: process.env.DB_NAME!,
encrypt: true,
},
};
// ツールの登録
server.setRequestHandler("tools/list", async () => {
return {
tools: [
{
name: "query_logs",
description: "エラーログを検索します",
inputSchema: {
type: "object",
properties: {
start_date: { type: "string", description: "開始日(YYYY-MM-DD)" },
end_date: { type: "string", description: "終了日(YYYY-MM-DD)" },
level: { type: "string", description: "ログレベル(ERROR/WARN/INFO)" },
},
required: ["start_date", "end_date"],
},
},
],
};
});
// ツールの実行ハンドラ
server.setRequestHandler("tools/call", async (request) => {
if (request.params.name === "query_logs") {
const { start_date, end_date, level } = request.params.arguments;
const results = await executeQuery(start_date, end_date, level);
return { content: [{ type: "text", text: JSON.stringify(results, null, 2) }] };
}
throw new Error("Unknown tool: " + request.params.name);
});
async function executeQuery(startDate: string, endDate: string, level?: string): Promise {
return new Promise((resolve, reject) => {
const connection = new Connection(config);
const results: any[] = [];
connection.on("connect", (err) => {
if (err) {
reject(err);
return;
}
let sql = "SELECT * FROM ErrorLogs WHERE timestamp BETWEEN @start AND @end";
if (level) sql += " AND level = @level";
const request = new Request(sql, (err) => {
if (err) reject(err);
else resolve(results);
});
request.addParameter("start", "VarChar", startDate);
request.addParameter("end", "VarChar", endDate);
if (level) request.addParameter("level", "VarChar", level);
request.on("row", (columns) => {
const row: any = {};
columns.forEach((column) => {
row[column.metadata.colName] = column.value;
});
results.push(row);
});
connection.execSql(request);
});
connection.connect();
});
}
async function main() {
const transport = new StdioServerTransport();
await server.connect(transport);
}
main().catch(console.error); このコードでは、query_logsという名前のツールを定義し、日付範囲とログレベルを指定してエラーログを検索できるようにしています。
実際の運用では、集計用ツール、ユーザー検索ツールなど、チームのニーズに応じて複数のツールを追加していきます。
Claude Desktop Appへの設定
構築したMCPサーバーをClaudeデスクトップアプリに登録します。
設定ファイル(macOSの場合は~/Library/Application Support/Claude/claude_desktop_config.json)に以下を追加します。
{
"mcpServers": {
"company-db": {
"command": "node",
"args": ["/path/to/mcp-db-server/dist/index.js"],
"env": {
"DB_SERVER": "your-server.database.windows.net",
"DB_USER": "admin",
"DB_PASSWORD": "********",
"DB_NAME": "production"
}
}
}
}Claudeアプリを再起動すると、左下のツールアイコンにMCPサーバーが表示され、利用可能になります。
IT女子 アラ美セキュリティ設計:本番環境での認証・アクセス制御戦略
MCPで社内データベースに接続する際、最も重要なのはセキュリティ設計です。
導入時に経験したインシデントと、その対策を共有します。
初期導入時のセキュリティインシデント
導入初期、テストユーザーに全権限を持つデータベースアカウントを渡してしまったことがありました。
ある日、チームメンバーが誤って「全ユーザーのメールアドレスを表示して」とClaudeに依頼し、個人情報が一覧表示されてしまったのです。
幸いテスト環境だったため実害はありませんでしたが、本番環境だったら大問題になっていました。
この経験から、以下の3つのセキュリティレイヤーを設けるようにしました。
レイヤー1:データベースレベルの権限制限
MCPサーバー用に専用の読み取り専用アカウントを作成し、必要最小限のテーブルへのSELECT権限のみを付与します。
-- 専用ユーザーの作成
CREATE USER mcp_readonly WITH PASSWORD 'secure_password';
-- 特定テーブルへの読み取り権限のみ付与
GRANT SELECT ON ErrorLogs TO mcp_readonly;
GRANT SELECT ON AccessLogs TO mcp_readonly;
GRANT SELECT ON PerformanceMetrics TO mcp_readonly;
-- 個人情報テーブルへのアクセスは明示的に拒否
REVOKE ALL ON Users FROM mcp_readonly;これにより、Claudeが誤って機密情報にアクセスすることを防げます。
レイヤー2:MCPサーバー内でのクエリ検証
MCPサーバー側でも、実行されるSQLクエリを検証します。
以下のように、ホワイトリスト方式で許可するクエリパターンを定義します。
const ALLOWED_TABLES = ["ErrorLogs", "AccessLogs", "PerformanceMetrics"];
const FORBIDDEN_KEYWORDS = ["DROP", "DELETE", "UPDATE", "INSERT", "TRUNCATE"];
function validateQuery(tableName: string, operation: string): boolean {
if (!ALLOWED_TABLES.includes(tableName)) {
throw new Error("Table " + tableName + " is not accessible");
}
if (FORBIDDEN_KEYWORDS.some(keyword => operation.toUpperCase().includes(keyword))) {
throw new Error("Operation contains forbidden keyword");
}
return true;
}この検証により、意図しない更新・削除クエリの実行を防止できます。
また、Python例外処理実践ガイドで紹介したエラーハンドリング手法を応用すると、MCPサーバーの堅牢性が向上します。
レイヤー3:監査ログの記録
全てのMCP経由のデータベースアクセスをログに記録します。
async function logAccess(user: string, tool: string, params: any, result: any) {
const logEntry = {
timestamp: new Date().toISOString(),
user,
tool,
params,
resultRowCount: Array.isArray(result) ? result.length : 0,
ipAddress: process.env.USER_IP,
};
await fs.appendFile("audit.log", JSON.stringify(logEntry) + "\n");
}このログを定期的にレビューすることで、不正アクセスや異常なパターンを早期に発見できます。
IT女子 アラ美実装パターンと導入効果の検証(ケーススタディ)
IT女子 アラ美MCPの実装経験は転職市場でも非常に高く評価されています
法人向けWordPress専用ホスティングサービス【XServer for WordPress】
状況(Before)
鈴木さん(仮名・33歳・バックエンドエンジニア・経験7年)のチームでは、社内データベースへの問い合わせ対応が属人化していました。
- DB権限を持つメンバーが2名しかおらず、問い合わせが集中していた
- 簡単な集計依頼でも平均対応時間が45分かかっていた
- 月間の問い合わせ件数が約120件に達し、本来の開発業務を圧迫していた
行動(Action)
鈴木さん(仮名)はClaude MCPを活用した以下の改善策を段階的に導入しました。
- Read Only権限のMCPサーバーをTypeScriptで構築し、安全なDB連携基盤を整備した
- よくある問い合わせパターンをテンプレート化し、非エンジニアでも使えるガイドを整備した
- クエリのホワイトリスト制御と監査ログの仕組みを実装した
結果(After)
導入後1か月の改善結果は以下のとおりです。
- 平均対応時間が45分から13分に短縮(70%削減)
- 非エンジニアが自力で解決できるケースが月80件以上に増加
- DB権限者への依頼が月120件から35件に減少
鈴木さん(仮名)は「テンプレート集の整備が最も効果的だった。非エンジニアでも自然言語で問い合わせできるようになり、依頼の大半が自己解決に変わった」と振り返っています。ツール導入だけでなく、使い方のガイド整備が定着の鍵という教訓です。
以下では、MCPの実装パターンをチームのニーズに応じて紹介します。
実践した3つの代表的なパターンを見ていきましょう。
パターン1:自然言語からSQLを生成する簡易型
最もシンプルなのは、ユーザーの質問を受けてClaudeがSQL文を生成し、それをMCPサーバーが実行する方式です。
server.setRequestHandler("tools/call", async (request) => {
if (request.params.name === "natural_query") {
const { question } = request.params.arguments;
// Claudeに最適なSQLを提案させる(実際にはプロンプト内で実施)
const suggestedSQL = await generateSQL(question);
// SQLを検証してから実行
validateQuery(suggestedSQL);
const results = await executeSQL(suggestedSQL);
return {
content: [
{ type: "text", text: "実行したSQL: " + suggestedSQL },
{ type: "text", text: JSON.stringify(results, null, 2) }
]
};
}
});この方式の利点は、柔軟性が高く、予期しない質問にも対応できることです。
ただし、生成されるSQLの精度がClaudeの理解度に依存するため、複雑なクエリでは誤った結果が返る可能性があります。
パターン2:定型クエリをツール化する堅実型
よく使われる集計や検索パターンを事前にツールとして定義する方式です。
チームでは、以下のようなツールを用意しました。
- get_error_summary:期間指定でエラーログをレベル別に集計
- find_slow_queries:実行時間が閾値を超えたクエリを検索
- analyze_user_activity:特定ユーザーのアクティビティを時系列で表示
この方式では、各ツールに対応するSQLがサーバー側で固定されているため、予期しない動作が起きにくくなります。
const TOOL_SQL_MAP: Record = {
get_error_summary: "SELECT level, COUNT(*) as count, DATE(timestamp) as date FROM ErrorLogs WHERE timestamp BETWEEN @start AND @end GROUP BY level, DATE(timestamp) ORDER BY date DESC",
find_slow_queries: "SELECT query, duration_ms, timestamp FROM QueryLogs WHERE duration_ms > @threshold ORDER BY duration_ms DESC LIMIT 50",
}; 運用開始から2週間後、チームメンバーから「このツール使いやすい!」という声が増え、利用率が急上昇しました。
パターン3:グラフ生成まで含める高度型
単なる数値の羅列ではなく、Claudeに集計結果をグラフ化させる方式です。
MCPサーバーがデータを返した後、Claudeがそのデータを解釈し、適切なグラフ形式(棒グラフ、折れ線グラフ等)を提案します。
チームでは、Canvas機能と組み合わせることで、Claudeが直接HTMLとChart.jsを使ったグラフを生成するようにしました。
これにより、「先週のエラー推移をグラフで見せて」といった要求に即座に応えられるようになりました。
従来方式では平均43分かかっていた対応が、MCP導入後4週間で平均12分にまで短縮されています。
この効果は、単にツールを導入しただけでなく、チーム全体でMCPの使い方を学習した結果でもあります。
IT女子 アラ美運用ノウハウ:チームでMCPを活用するためのルール設計
技術的な実装が完了しても、チーム全体で効果的に活用するには運用ルールが不可欠です。
実践して効果があったルール設計を紹介します。
利用ガイドラインの整備
MCPを使い始める前に、全メンバーに以下のガイドラインを共有しました。
- アクセス可能なデータの範囲:どのテーブルにアクセスできるかを明記
- 禁止事項:個人情報の一括ダウンロード、業務時間外のアクセス等を禁止
- 推奨される質問例:効果的な問い合わせ方を具体例で示す
特に重要なのは、「どんな質問をすればいいかわからない」というメンバーへの支援です。
初期段階でよくある質問テンプレート集を作成し、Notionで共有しました。
よくある質問テンプレート
エラーログの確認
「昨日から今日までのERRORレベルのログを件数順に表示して」
パフォーマンス分析
「過去1週間で実行時間が1秒を超えたクエリのTOP10を教えて」
ユーザー行動分析
「特定ユーザー(ID: 12345)の過去3日間のアクセス履歴を時系列で表示して」このテンプレートを公開してから、利用率が約2倍に増加しました。
定期的なレビューセッション
月1回、チーム全体でMCPレビューセッションを開催しています。
ここでは以下のトピックを扱います。
- よく使われたツールの紹介:他のメンバーが知らない便利な使い方を共有
- 改善提案:新しいツールの追加要望や既存ツールの改良案を議論
- セキュリティインシデントの報告:もしあれば、原因と対策を全員で共有
あるレビューセッションで、営業チームのメンバーから「顧客別の売上推移も見たい」という要望があり、新しいツールを追加しました。
このように、運用しながら継続的に改善することで、MCPの価値が高まっていきます。
段階的なロールアウト戦略
全メンバーに一度に展開するのではなく、以下のような段階的導入を行いました。
- フェーズ1(1週間):開発チームのみで試験運用
- フェーズ2(2週間):PjMと技術リードに拡大、フィードバック収集
- フェーズ3(1ヶ月):全社展開、オンボーディングドキュメント整備
この段階的アプローチにより、初期のバグや使いにくさを早期に発見し、本格展開時にはスムーズに浸透させることができました。
また、OpenTelemetry実践ガイドで解説した分散トレーシング手法を導入すれば、MCPサーバーのパフォーマンス分析も容易になります。
IT女子 アラ美よくある質問
MCPサーバーの構築にどのくらいの工数がかかる?
基本的な読み取り専用のMCPサーバーなら1〜2日で構築可能です。TypeScriptのMCP SDKが充実しているため、データベース接続とツール定義を実装するだけで動作します。セキュリティ設計や監査ログの実装を含めても、1週間あれば本番運用に耐えるものが構築できます。
社内DBへの書き込み操作もMCPで実現できる?
技術的には可能ですが、初期導入ではRead Only権限に限定することを強く推奨します。書き込み操作はデータ破損のリスクがあるため、まずは読み取り専用で運用実績を積み、十分な監査体制が整ってから段階的に書き込み機能を追加するのが安全です。
MCPのセキュリティリスクをどう管理すればいい?
Read Only権限、クエリのホワイトリスト制御、監査ログの3つが基本です。特にクエリのホワイトリスト制御を導入することで、意図しないテーブルへのアクセスを防止できます。加えて、アクセストークンの定期ローテーションとIPアドレス制限を組み合わせることで、堅牢なセキュリティ体制を構築できます。
IT女子 アラ美おすすめのAI学習・キャリアサービスを比較
Claude MCPの実装スキルはAI人材として市場価値を大きく高めます。ハイクラスなポジションを目指す方はハイクラスエンジニア転職エージェント3社比較も参考にしてみてください。以下のサービスでキャリアの可能性を広げてみてください。
本記事で解説したようなAI技術を、基礎から体系的に身につけたい方は、以下のスクールも検討してみてください。
| 比較項目 | Winスクール | Aidemy Premium |
|---|---|---|
| 目的・ゴール | 資格取得・スキルアップ初心者〜社会人向け | エンジニア転身・E資格Python/AI開発 |
| 難易度 | 個人レッスン形式 | コード記述あり |
| 補助金・給付金 | 教育訓練給付金対象 | 教育訓練給付金対象 |
| おすすめ度 | 幅広くITスキルを学ぶなら | AIエンジニアになるなら |
| 公式サイト | 詳細を見る | − |
IT女子 アラ美まとめ
本記事では、Claude MCPを活用した社内データベース連携の実践手順を解説しました。
MCPはセキュリティ設計を適切に行えば、問い合わせ対応時間を大幅に削減できる強力なツールです。
チームでは導入から4週間で平均対応時間を70%短縮し、メンバーの満足度も向上しました。
重要なのは、技術的な実装だけでなく、チーム全体での運用ルール設計と継続的な改善サイクルです。
まずは小規模なチームで試験導入し、フィードバックを集めながら段階的に拡大していくことをお勧めします。
あなたのチームでも、Claude MCPを活用して社内データを最大限に活用してみてはいかがでしょうか。
IT女子 アラ美