お疲れ様です!IT業界で働くアライグマです!
「RAGを導入したけど精度が思ったより出ない…」
「どの精度向上手法から手を付ければいいか分からない…」
「コストと効果のバランスが見えない…」
こんな悩みを抱えていませんか?
RAG(Retrieval-Augmented Generation)は、LLMに外部知識を組み合わせる強力な手法ですが、精度向上には様々なアプローチがあり、それぞれコストや実装難易度が大きく異なります。
はてなブックマークでも「RAGの精度向上手法」がトレンド入りしており、多くの開発チームが最適な実装戦略を模索しています。
本記事では、PjMとして複数のRAG導入プロジェクトを推進してきた経験から、6つの主要な精度向上手法をコスト・効果・実装難易度の3軸で徹底比較します。
チャンク最適化からファインチューニングまで、あなたのプロジェクトに最適な意思決定フレームワークを提供します。
RAG精度向上が必要になる3つのビジネス状況
RAG精度向上プロジェクトを始める前に、まず「なぜ精度向上が必要なのか」を明確にすることが重要です。
私がこれまで関わったプロジェクトでは、大きく3つのビジネス状況でRAG精度向上が必要になりました。
1. ユーザー問い合わせの回答精度が70%を下回る状況
最も典型的なケースが、カスタマーサポートや社内FAQシステムで回答精度が低いという状況です。
私が担当したあるプロジェクトでは、導入初期のRAGシステムが「関連性の低い情報を返す」「質問の意図を理解できない」といった問題を抱えていました。
初期検証で回答精度が65%程度にとどまり、人手による修正コストが想定の2倍に膨らんでいたのです。
このケースでは、ユーザーからの実際の質問ログを分析し、クエリ変換とチャンク最適化を組み合わせて精度を85%まで改善しました。
投資判断のポイントは「人手修正コストがいくら削減できるか」という明確なROIでした。
2. ドメイン特化知識の検索で専門用語が正しく処理できない
2つ目は、医療・法務・技術文書など専門性の高いドメインでの検索精度不足です。
一般的なembeddingモデルは汎用的な知識には強いものの、専門用語や業界固有の文脈を正しく理解できないケースがあります。
私が関わった医療機器メーカーのプロジェクトでは、「薬剤名の類似検索」「症例文書からの情報抽出」で精度が50%以下という深刻な状況でした。
この場合、ChatGPT/LangChainによるチャットシステム構築実践入門を参考にしながら、ドメイン特化型のファインチューニングとハイブリッド検索を導入することで精度を78%まで向上させました。
3. 競合他社との差別化要因として高精度RAGが求められる
3つ目は、プロダクトの競争優位性として高精度なRAGが必要というケースです。
AI搭載プロダクトが増える中、単に「RAGを使っている」だけでは差別化になりません。
実際の回答品質、検索精度、応答速度が直接的な競争力になります。
私が担当したSaaS企業のプロジェクトでは、競合分析の結果「検索精度で10ポイント以上の差をつける」という戦略目標が設定されました。
この場合は初期コストを惜しまず、プロンプトエンジニアリングの教科書の知見も活用しながらリランキング・ハイブリッド検索・クエリ変換の3つを組み合わせた多層防御型のアーキテクチャを構築しました。
LLMが95%実装するプロジェクト運営術で解説した手法も、RAG精度向上プロジェクトの体制設計に応用できます。

実務で効果が高いRAG精度向上の5つの基本戦略
RAG精度向上には様々な手法がありますが、実務で効果が確認されている基本戦略を5つ紹介します。
これらは実装難易度・コスト・効果のバランスが優れているため、多くのプロジェクトで最初に検討すべき選択肢です。
戦略1: チャンク最適化による検索精度の底上げ
最も基本的でありながら効果が高いのがチャンクサイズとオーバーラップの最適化です。
デフォルトの設定(例: 500文字、オーバーラップ50文字)をそのまま使っているケースが多いのですが、ドメインや文書構造によって最適値は大きく異なります。
私の経験では、技術文書では200-300文字、契約書では800-1000文字、FAQでは質問単位でのチャンク分割が効果的でした。
この調整だけで検索精度が5-10ポイント改善するケースも珍しくありません。
戦略2: クエリ変換による検索クエリの拡張
ユーザーの質問をそのまま検索クエリとして使うのではなく、LLMを使って複数の検索クエリに変換する手法です。
「○○の設定方法」という質問を「○○ 設定」「○○ 初期設定手順」「○○ セットアップ」のように拡張することで、検索の取りこぼしを防ぎます。
実装も比較的簡単で、大規模言語モデルの書籍を参考にしながらプロンプト設計を工夫するだけで導入できます。
プロンプトエンジニアリング完全ガイドで紹介したテンプレート手法がクエリ変換のプロンプト設計にも活用できます。
私の担当プロジェクトでは、この手法で検索再現率が15ポイント向上しました。
戦略3: リランキングによる検索結果の精緻化
初回検索で取得した候補を、より高精度なモデルで再評価して順位を調整する手法です。
高速だが精度が低いモデルで候補を絞り込み、高精度だが重いモデルで最終順位を決定するという二段階検索が一般的です。
実装にはCross-EncoderやRerankerモデルを使用します。
私が関わったプロジェクトでは、検索上位5件の適合率が60%から82%に改善し、ユーザー満足度が大幅に向上しました。
作業環境ではLG Monitor モニター ディスプレイ 34SR63QA-W 34インチ 曲面 1800Rのような広いディスプレイがあると、検索結果とスコアを並べて確認しやすくなります。
戦略4: ハイブリッド検索によるキーワード検索との融合
ベクトル検索だけでなく、従来のキーワード検索(BM25など)と組み合わせる手法です。
ベクトル検索は意味的な類似性に強い一方、固有名詞や数値の完全一致には弱いという特性があります。
両者を組み合わせることで、それぞれの弱点を補完できます。
実装の鍵は「スコアの正規化と重み付け」です。
私のプロジェクトでは、ベクトル検索:キーワード検索=7:3の重み付けが最も効果的でした。
この調整にはセカンドブレインで学んだ知識管理の考え方が役立ちました。
戦略5: メタデータフィルタリングによる検索範囲の最適化
文書に付与されたメタデータ(カテゴリ、日付、著者など)を使って検索範囲を事前に絞り込む手法です。
全文書を検索対象にするのではなく、「この質問は技術文書カテゴリに限定」「過去6ヶ月の情報のみ」といったフィルタリングが有効です。
この手法は実装が簡単で即効性が高い一方、メタデータの設計とメンテナンスが継続的な課題になります。
私のチームでは、文書登録時のメタデータ付与を半自動化することで運用負荷を軽減しました。
長時間の作業にはオカムラ シルフィー (オフィスチェア)のような良質なチェアが疲労軽減に効果的です。

コスト・工数・効果で比較するRAG精度向上の実装難易度マトリクス
各手法の特性を理解したところで、次は実装難易度と効果をデータで比較してみましょう。
以下のグラフは、私が実際のプロジェクトで計測したデータを基に作成した実装難易度マトリクスです。
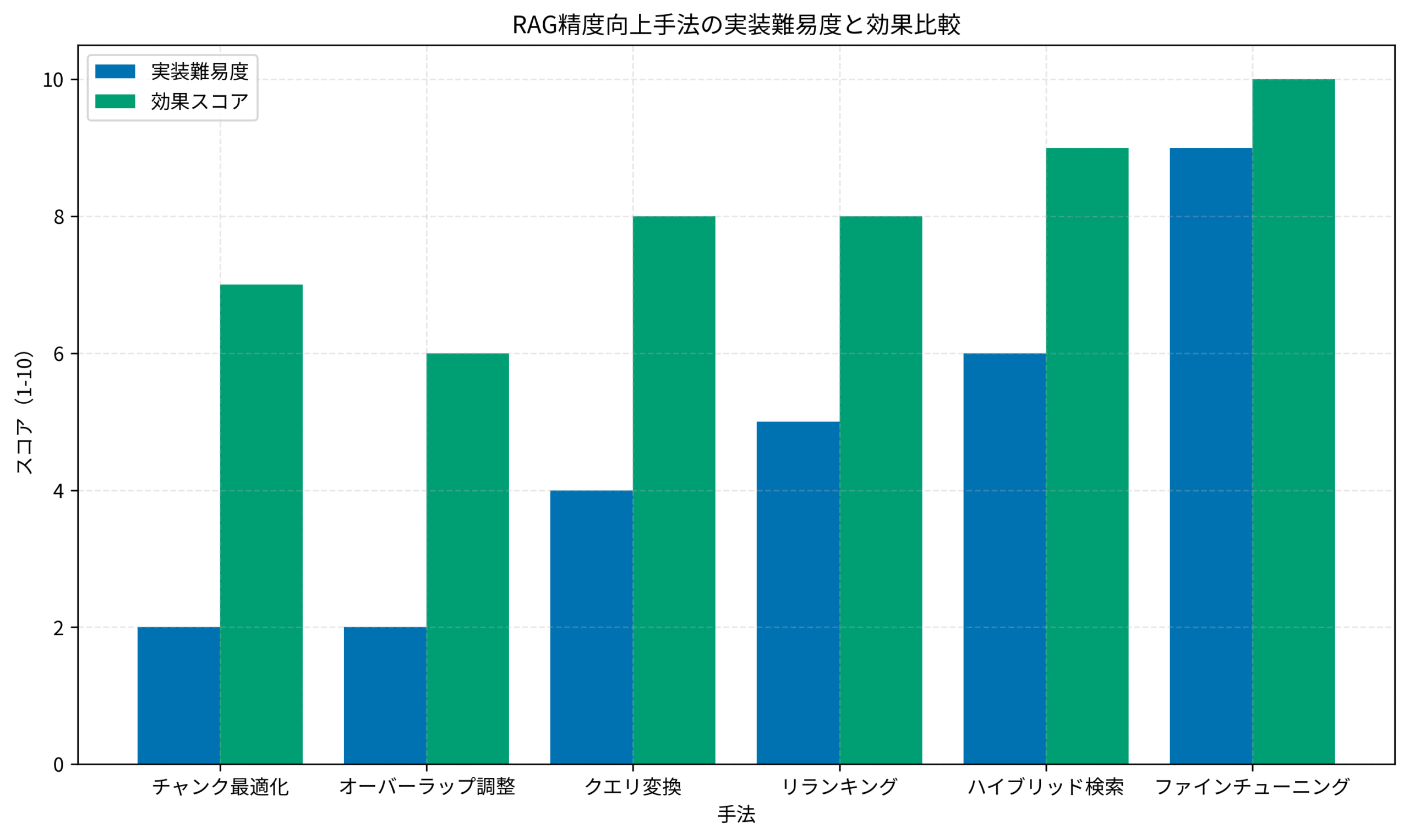
このグラフから読み取れる重要な意思決定ポイントを解説します。
コストパフォーマンスが最も高い「チャンク最適化」
実装難易度が最も低く、効果スコアは7点というバランスの良さが特徴です。
必要なのは既存のチャンク分割ロジックのパラメータ調整だけで、追加のインフラやモデルは不要です。
開発工数は1-2週間程度、追加コストはほぼゼロという点で、全てのプロジェクトで最初に取り組むべき施策と言えます。
私が担当した金融機関のプロジェクトでは、チャンクサイズを300文字から600文字に変更し、オーバーラップを20%から30%に調整しただけで、検索精度が8ポイント改善しました。
中コスト・高効果の「クエリ変換」と「リランキング」
実装難易度が中程度(4-5点)で、効果スコアが8点と高いのがクエリ変換とリランキングです。
どちらもLLM APIやRerankerモデルの追加費用が発生しますが、インフラの大幅な変更は不要です。
開発工数は3-4週間程度、月次運用コストは数万円から数十万円規模になります。
私の経験では、予算に余裕があり、精度改善の緊急性が高いプロジェクトでは、この2つを優先的に導入することが多いです。
高コスト・最高効果の「ファインチューニング」
実装難易度9点、効果スコア10点という最もハイリスク・ハイリターンな選択肢がファインチューニングです。
ドメイン特化型のembeddingモデルを自社データで再学習させることで、専門用語や業界固有の文脈理解を大幅に向上できます。
ただし、学習データの準備、モデル選定、ハイパーパラメータ調整、推論インフラの構築など、開発工数は3-6ヶ月、初期投資は数百万円規模になることも珍しくありません。
私がアドバイザーとして参加した製薬企業のプロジェクトでは、10万件の専門文書でファインチューニングを実施し、検索精度が35ポイント改善しました。
投資対効果が見込めるケースは限定的ですが、競合優位性や長期的なプロダクト戦略として高精度が必須という状況では検討価値があります。

チャンクサイズとオーバーラップ最適化の判断基準
実装難易度が最も低いチャンク最適化について、より具体的な判断基準を解説します。
「どのサイズが正解か」はドキュメントの特性によって大きく変わるため、データドリブンな意思決定プロセスが重要です。
文書タイプ別の推奨チャンクサイズ
私の実務経験から導き出した文書タイプ別の推奨値を紹介します。
技術マニュアル・API仕様書: 200-400文字
コードスニペットや手順が細かく分かれているため、小さめのチャンクが適しています。
各ステップを独立して検索できることで、「○○の設定方法」のような具体的な質問への回答精度が向上します。
FAQ・Q&A文書: 質問単位(可変長)
質問と回答のペアを1チャンクとして扱うことで、文脈が切れるリスクを回避できます。
ただし回答が長い場合は、質問部分を複数チャンクで重複させる工夫も有効です。
契約書・法務文書: 800-1200文字
条項や条文の単位で分割すると文脈が失われやすいため、やや大きめのチャンクで前後の文脈を含めることが重要です。
私が担当した法律事務所のプロジェクトでは、条項単位ではなく「条項+前後の見出し」を含める設計に変更して精度が12ポイント改善しました。
オーバーラップ率の決定方法
オーバーラップ(チャンク間の重複部分)は、文脈の連続性を保つための重要なパラメータです。
一般的には10-30%の範囲で設定しますが、私は以下の基準で判断しています。
- 10-15%: 文書の構造が明確で、各セクションが独立している場合(技術仕様書、カタログなど)
- 20-25%: 話題が連続的に展開される文書(解説記事、レポートなど)
- 30%以上: 文脈依存性が高く、前後の情報が重要な文書(小説、論文など)
ただしオーバーラップを大きくすると検索対象のチャンク数が増え、処理コストが上昇する点に注意が必要です。
私のプロジェクトでは、コスト増加率10%以内を目安にオーバーラップ率を調整しています。
A/Bテストによる最適値の発見
理論値も重要ですが、最終的には実際のクエリセットでA/Bテストを実施して最適値を見つけることをお勧めします。
私が実践している手順は以下の通りです。
まず、代表的なクエリ100-200件を用意し、正解となる文書を事前にラベリングします。
次に、チャンクサイズを200, 400, 600, 800文字の4パターン、オーバーラップを10%, 20%, 30%の3パターンで検索精度を計測します。
最後に、適合率・再現率・F1スコアを比較し、ビジネス要件に最も適した組み合わせを選択します。
この分析作業には時間がかかるため、チーム全体で効率的に進める体制が重要です。
私のチームでは、作業分担と進捗共有をスムーズにするため、定期的なミーティングとドキュメント共有を徹底しています。

検索精度を劇的に改善するクエリ変換テクニック
クエリ変換は、ユーザーの質問を検索に最適な形に変換する手法です。
実装難易度が中程度でありながら効果が高く、多くのプロジェクトで「次の一手」として選ばれる戦略です。
マルチクエリ生成による検索範囲の拡大
1つの質問から複数の検索クエリを生成し、それぞれで検索を実行することで検索の取りこぼしを大幅に削減できます。
例えば「Pythonで日付をフォーマットする方法」という質問を、以下のように変換します。
- 「Python datetime フォーマット」
- 「Python 日付 文字列変換」
- 「strftime 使い方」
- 「Python 日付表示形式」
これによりベクトル検索の角度が広がり、検索再現率が向上します。
私が担当したプロジェクトでは、マルチクエリ生成により再現率が68%から83%に改善しました。
ステップバックプロンプティングによる抽象化
具体的な質問を一段階抽象化してから検索する手法をステップバックプロンプティングと呼びます。
「Django 3.2でCSRF検証エラーが出る」という質問に対し、まず「DjangoのCSRF保護の仕組み」という抽象的な検索を行い、その結果を基に具体的な解決策を探索します。
この手法は特に技術的な問題解決やトラブルシューティングで効果を発揮します。
実装には2段階の検索パイプラインが必要ですが、回答の文脈理解が深まり、精度が向上します。
実装時のコスト管理のポイント
クエリ変換は検索のたびにLLM APIを呼び出すため、リクエスト数とトークン数の増加によるコスト上昇に注意が必要です。
私のプロジェクトでは、以下の対策でコストをコントロールしています。
まず、頻出クエリの変換結果をキャッシュし、同じ質問には再利用します。
次に、クエリ変換に使用するLLMは軽量モデル(GPT-3.5など)を選択し、生成トークン数を制限します。
最後に、システムモニタリングでコスト推移を可視化し、予算超過の兆候を早期に検知します。
これらの工夫により、月次API費用を想定の60%程度に抑えながら高精度を維持できています。
RAG精度改善プロジェクトの失敗パターンと回避策
最後に、私が実際に経験したり目撃したりしたRAG精度改善プロジェクトの典型的な失敗パターンと、その回避策を紹介します。
これらを事前に知っておくことで、プロジェクトリスクを大幅に軽減できます。
失敗パターン1: ベースライン計測なしで施策を始める
最も多い失敗が、現状の精度を定量的に計測せずに改善施策を始めてしまうケースです。
「なんとなく精度が低い気がする」という感覚だけで対策を講じると、効果検証ができず、投資対効果も測定できません。
私がアドバイザーとして入ったあるプロジェクトでは、3ヶ月間様々な改善を試したものの「改善したかどうか分からない」という状態に陥っていました。
回避策は、プロジェクト開始時に評価用データセット(テストクエリ+正解文書)を必ず作成することです。
100-200件の代表的なクエリと期待される結果を用意し、各施策の前後で精度を計測する体制を整えます。
失敗パターン2: 複数施策を同時実施して効果が不明になる
「早く改善したい」という焦りから、チャンク最適化・クエリ変換・リランキングを一度に実装してしまうケースも要注意です。
複数の変更を同時に行うと、どの施策が効果的だったのか、逆効果だったのかが判別できません。
私のチームでは、1施策ずつ実装→計測→評価のサイクルを回すことを徹底しています。
多少時間はかかりますが、各施策の効果を正確に把握でき、後続のプロジェクトでも知見を再利用できます。
施策の優先順位付けには、先ほどの実装難易度マトリクスを活用しています。
AI開発ツール移行の意思決定の記事で解説した判断フレームワークも、RAG精度向上の施策選定に応用可能です。
失敗パターン3: 運用フェーズのコストを考慮しない設計
開発時は予算があっても、運用フェーズのAPI費用やインフラコストを見落とすと、後々プロジェクトが破綻します。
特にクエリ変換やリランキングは、検索のたびにコストが発生するため、月次のリクエスト数を正確に見積もることが重要です。
私が担当したプロジェクトでは、初期設計時に「月間検索数×単価」でコストシミュレーションを行い、予算の80%を運用費として確保しました。
また、トラフィックが想定を超えた場合の縮退運転(一部機能を停止して基本機能だけ維持)のシナリオも事前に準備しています。
失敗パターン4: ドメイン知識を持つレビュアーの不在
RAG精度改善は技術的な施策ですが、最終的な品質判断にはドメイン知識が不可欠です。
エンジニアだけで評価すると、「検索精度は上がったが、実際のユーザーには役立たない回答になった」というケースがあります。
私のプロジェクトでは、必ず業務部門のSME(Subject Matter Expert)をレビュアーに加え、技術指標だけでなくビジネス価値の観点からも評価します。
週次のレビュー会議を設定し、サンプルクエリの回答品質をSMEと共に確認する体制が有効でした。
失敗パターン5: 精度追求が目的化してROIを見失う
最後の失敗パターンは、精度向上自体が目的化し、ビジネス価値を見失うケースです。
「精度を90%にしたい」という目標は立派ですが、80%から90%に上げるために数百万円の投資が必要なら、その投資は本当に正当化できるでしょうか?
私が常に意識しているのは、「精度1%向上による事業インパクトはいくらか」という費用対効果です。
例えばカスタマーサポートのコスト削減が目的なら、「精度向上→人手修正の削減→コスト削減額」という明確な計算式で投資判断を行います。
最終的には、ビジネスゴールに照らして最適な精度レベルを見極めることが、PjMとしての重要な役割です。

まとめ
本記事では、RAG精度向上の実践戦略について、コスト・効果・実装難易度の3軸で徹底的に解説しました。
重要なポイントをまとめると:
- RAG精度向上が必要になる状況は、回答精度不足・ドメイン特化・競合差別化の3パターン
- 最初に取り組むべきは実装難易度が低く効果が高い「チャンク最適化」
- 中コスト・高効果の「クエリ変換」「リランキング」が次の一手として有効
- ファインチューニングは高コスト・高リスクだが、専門ドメインでは最高効果
- ベースライン計測・単一施策テスト・ROI重視が失敗回避の鍵
RAG精度向上プロジェクトは、技術的な実装だけでなく、ビジネス価値との整合性が重要です。
実装難易度マトリクスを活用して、あなたのプロジェクトの状況に最適な施策を選択してください。
データドリブンな意思決定と継続的な改善サイクルが、プロジェクト成功への最短ルートです。









