お疲れ様です!IT業界で働くアライグマです!
マイクロサービスアーキテクチャを導入したものの、「複数のサービス間でリクエストがどう流れているのか把握できない」「パフォーマンス低下の原因がどのサービスにあるのか特定できない」といった悩みを抱えていませんか。
実は、OpenTelemetryを導入することで、マイクロサービス環境全体のリクエストフローを可視化でき、ボトルネック特定が数分で完了します。
私自身、複数のマイクロサービスを運用する際に、サービス間のレイテンシ問題に毎週数時間を費やしていましたが、OpenTelemetryの分散トレーシングを導入してからは、問題の原因特定が劇的に高速化しました。
本記事では、OpenTelemetryの基本概念から実装パターン、Prometheus・Grafanaとの統合、実践的なトレーシング戦略まで、PjM視点での実装ノウハウをお伝えします。
OpenTelemetryの基本概念と分散トレーシングの重要性
OpenTelemetryとは何か
OpenTelemetryは、アプリケーションのテレメトリデータ(トレース・メトリクス・ログ)を統一的に収集・処理するためのオープンスタンダードです。CNCF(Cloud Native Computing Foundation)が主導するプロジェクトで、複数のベンダーに依存しない中立的なアプローチを提供します。
従来のモニタリングでは、各サービスが独自のログやメトリクスを出力していたため、サービス間の関連性を把握するのが困難でした。OpenTelemetryは、リクエストが複数のサービスを通過する際に、一意のトレースIDで追跡できる仕組みを提供します。
分散トレーシングがマイクロサービスで必須な理由
マイクロサービスアーキテクチャでは、1つのユーザーリクエストが複数のサービスを経由します。例えば、ECサイトの注文処理では、API Gateway→Order Service→Payment Service→Inventory Service→Notification Serviceという流れが発生します。
このフロー全体で、どのサービスが遅いのか、どこでエラーが発生しているのかを把握するには、リクエスト全体を一つの「トレース」として追跡する必要があります。OpenTelemetryはこれを実現します。
PjM視点での導入メリット
私の経験では、OpenTelemetryの導入により以下のメリットが得られました:
- 問題特定時間の短縮:従来は数時間かかっていたボトルネック特定が、15分以内に完了
- 本番環境での信頼性向上:サービス間の依存関係が明確になり、デプロイ前のリスク評価が正確に
- チーム間のコミュニケーション改善:トレースデータを共有することで、各チームが問題を客観的に理解
- スケーリング判断の最適化:どのサービスがスケールボトルネックかが明確になり、無駄なリソース投資を削減
NIST Cybersecurity Framework 2.0実装ガイドでは、セキュリティ体制構築を解説していますが、OpenTelemetryの導入もシステムの可視化と信頼性向上に不可欠です。
OpenTelemetryの基礎を学ぶには、専門書籍入門 OpenTelemetry ―現代的なオブザーバビリティシステムの構築と運用を参考にすることで、実装の全体像を体系的に理解できます。

OpenTelemetryのアーキテクチャと主要コンポーネント
OpenTelemetryの3つの柱:トレース・メトリクス・ログ
OpenTelemetryは、テレメトリデータを3つのカテゴリに分類します:
- トレース(Traces):リクエストがシステム全体を通過する際の経路と時間情報。分散トレーシングの中核
- メトリクス(Metrics):CPU使用率、メモリ、リクエスト数など、時系列データ。Prometheusと連携
- ログ(Logs):アプリケーションが出力するテキストログ。トレースIDと紐付けることで、コンテキスト情報を保持
これら3つを統一的に収集することで、問題発生時に「いつ」「どこで」「何が」起きたのかを多角的に分析可能になります。
Collector・Exporter・Instrumentationの役割
OpenTelemetryの実装には、以下の主要コンポーネントが関わります:
- Instrumentation(計測):アプリケーション内にOpenTelemetry SDKを組み込み、トレースデータを生成
- Collector(収集):各サービスから送信されたテレメトリデータを受け取り、フィルタリング・変換・エクスポート
- Exporter(エクスポート):処理済みデータをJaeger・Prometheus・Datadogなどのバックエンドに送信
実装では、各サービスにInstrumentationを組み込み、Collectorで一元管理し、複数のバックエンドにエクスポートするアーキテクチャが標準的です。
Docker開発環境構築では、チーム開発効率を向上させる実装メソッドを解説していますが、OpenTelemetryの段階的導入もこうした環境構築の重要な要素です。
分散システムの設計原則を学ぶには、専門書籍分散システムデザインパターン ―コンテナを使ったスケーラブルなサービスの設計を参考にすることで、OpenTelemetryの配置戦略をより深く理解できます。
実装パターン:SDK vs Agent
OpenTelemetryの導入方法は2つあります:
- SDK方式:アプリケーションコード内にOpenTelemetry SDKを直接組み込む。細かい制御が可能だが、コード変更が必要
- Agent方式:OpenTelemetry Agentをサイドカーとしてデプロイ。アプリケーションコード変更が最小限で済む
PjM視点では、既存システムへの影響を最小化するため、Agent方式から始めて、段階的にSDK方式に移行する戦略が推奨されます。

Prometheus・Grafanaとの統合による可視化戦略
OpenTelemetry Collectorの設定と運用
OpenTelemetry Collectorは、テレメトリデータの「ハブ」として機能します。複数のサービスから送信されたデータを受け取り、フィルタリング・サンプリング・変換を行い、複数のバックエンドに送信します。
実装では、Receiver設定(どのプロトコルでデータを受け取るか)、Processor設定(バッチ処理・サンプリング・属性追加)、Exporter設定(複数のバックエンドへの送信先)が重要です。
Kubernetesで運用する場合、CollectorをサイドカーまたはDaemonSetとしてデプロイし、各ノードでテレメトリデータを集約するアーキテクチャが標準的です。
Prometheusメトリクスの抽出と活用
OpenTelemetryから生成されるメトリクスは、Prometheusフォーマットでエクスポート可能です。これにより、既存のPrometheus・Grafana環境とシームレスに統合できます。
重要なメトリクスには、各サービスの処理時間分布(p50・p95・p99)、サービスごとのエラー発生率、秒単位のリクエスト処理数が含まれます。これらをGrafanaダッシュボードで可視化することで、リアルタイムでシステムの健全性を監視可能になります。
Jaegerによる分散トレーシングの詳細分析
Jaegerは、OpenTelemetryから送信されたトレースデータを保存・検索・可視化するバックエンドです。UI上で、リクエストがどのサービスを通過し、各サービスでどの程度の時間を費やしたかを視覚的に確認できます。
トレース検索でトレースIDやサービス名で検索し、特定のリクエストの詳細を確認、レイテンシ分析でサービス間のレイテンシを比較してボトルネックを特定、エラートレースでエラーが発生したリクエストのトレースを追跡して原因を特定できます。
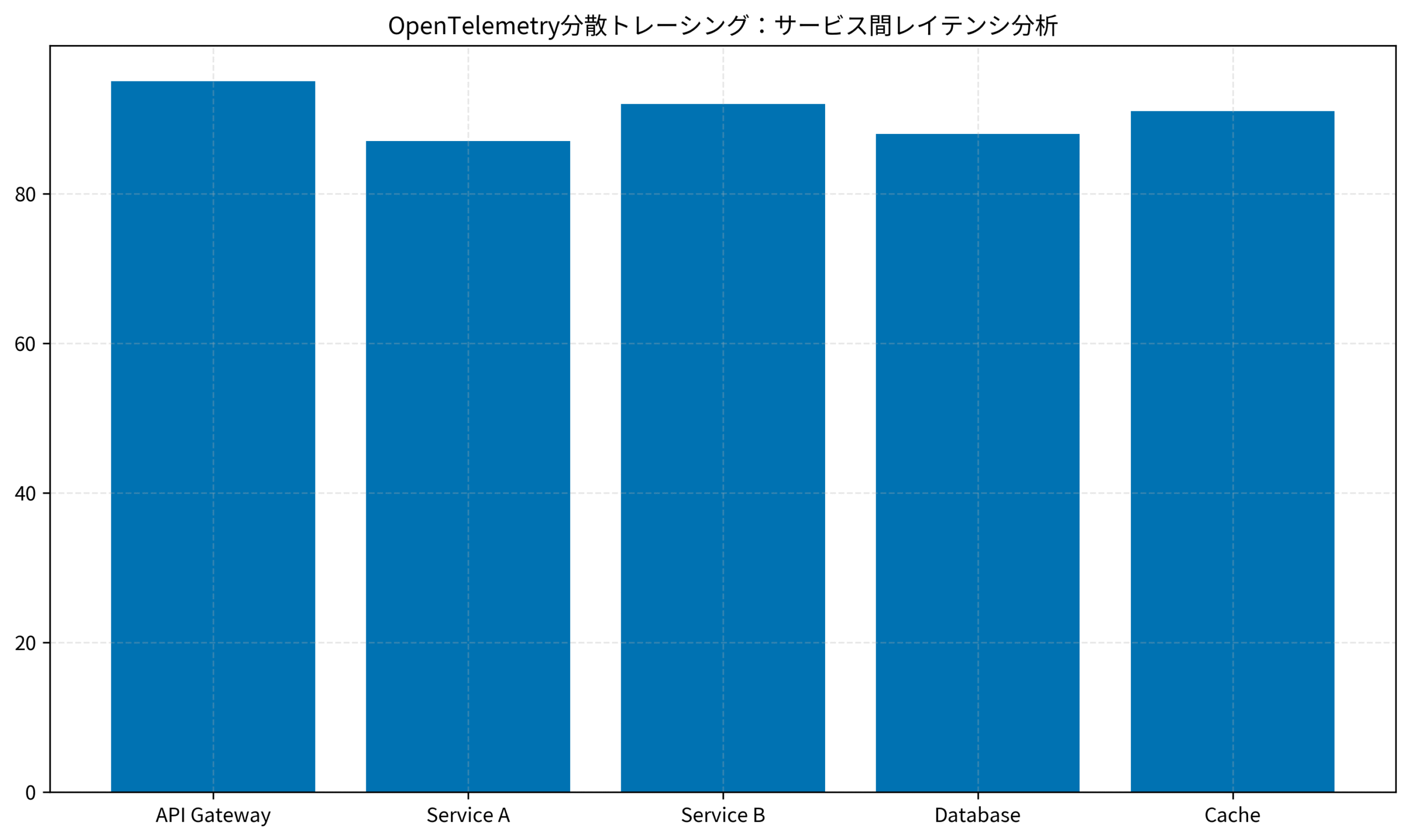
グラフは、OpenTelemetryで計測した各サービスのレイテンシを示しています。API Gatewayが95msで最も高く、次にService Bが92msとなっており、これらがボトルネックの候補です。このデータを基に、キャッシング戦略やスケーリング判断を行います。
Prometheusモニタリングでは、メトリクス収集の基本を解説していますが、OpenTelemetryはそれをさらに高度な分散トレーシングで補完します。
マイクロサービスアーキテクチャの全体像を把握するには、専門書籍マイクロサービスアーキテクチャ 第2版を参考にすることで、OpenTelemetryの配置戦略が明確になります。
実装パターン:Python・Node.js・Goでの計測方法
Python(FastAPI)での実装例
Pythonでの実装は、OpenTelemetry SDKとFastAPI用のInstrumentationを組み合わせます。以下は基本的な実装パターンです:
from fastapi import FastAPI
from opentelemetry import trace
from opentelemetry.exporter.jaeger.thrift import JaegerExporter
from opentelemetry.sdk.trace import TracerProvider
from opentelemetry.sdk.trace.export import BatchSpanProcessor
from opentelemetry.instrumentation.fastapi import FastAPIInstrumentor
app = FastAPI()
jaeger_exporter = JaegerExporter(agent_host_name="localhost", agent_port=6831)
trace.set_tracer_provider(TracerProvider())
trace.get_tracer_provider().add_span_processor(BatchSpanProcessor(jaeger_exporter))
FastAPIInstrumentor.instrument_app(app)
@app.get("/order")
async def create_order():
tracer = trace.get_tracer(__name__)
with tracer.start_as_current_span("create_order"):
return {"order_id": 123}
このコードにより、FastAPIアプリケーションのすべてのエンドポイントが自動的に計測され、Jaegerに送信されます。
FastAPI実装パターンでは、高速APIサーバー構築の設計手法を解説していますが、OpenTelemetryの計測を組み込むことで、本番環境での信頼性がさらに向上します。
Prometheusの実践的な監視システムの構築方法を学ぶには、専門書籍Prometheus実践ガイド: クラウドネイティブな監視システムの構築を参考にすることで、OpenTelemetryとの統合がスムーズになります。
Node.js(Express)での実装例
Node.jsでの実装も同様に、OpenTelemetry SDKとExpress用のInstrumentationを使用します:
const express = require('express');
const { NodeTracerProvider } = require('@opentelemetry/node');
const { JaegerExporter } = require('@opentelemetry/exporter-jaeger');
const { BatchSpanProcessor } = require('@opentelemetry/tracing');
const app = express();
const jaegerExporter = new JaegerExporter({
serviceName: 'order-service',
host: 'localhost',
port: 6831,
});
const tracerProvider = new NodeTracerProvider();
tracerProvider.addSpanProcessor(new BatchSpanProcessor(jaegerExporter));
app.get('/order', (req, res) => {
res.json({ order_id: 123 });
});
app.listen(3000);
Go(Gin)での実装例
Goでの実装は、以下のようになります:
package main
import (
"github.com/gin-gonic/gin"
"go.opentelemetry.io/otel"
"go.opentelemetry.io/otel/exporters/jaeger"
"go.opentelemetry.io/otel/sdk/trace"
)
func main() {
exporter, _ := jaeger.New(jaeger.WithAgentHost("localhost"))
tp := trace.NewTracerProvider(trace.WithBatcher(exporter))
otel.SetTracerProvider(tp)
router := gin.Default()
router.GET("/order", func(c *gin.Context) {
tracer := otel.Tracer("order-service")
ctx, span := tracer.Start(c.Request.Context(), "create_order")
defer span.End()
c.JSON(200, gin.H{"order_id": 123})
})
router.Run(":3000")
}
サンプリング戦略と本番環境での運用最適化
サンプリングレートの設定と調整
本番環境では、すべてのリクエストをトレースするとデータ量が膨大になり、ストレージコストが増加します。OpenTelemetryでは、AlwaysOnSampler(すべてのトレースを記録)、AlwaysOffSampler(トレースを記録しない)、TraceIdRatioBased(指定した割合のトレースを記録)、ParentBasedSampler(親スパンのサンプリング決定に基づいて判定)などのサンプリング方式が提供されます。
PjM視点では、本番環境ではTraceIdRatioBased(5~10%)から始めて、問題発生時に100%に切り替える戦略が推奨されます。
Redisキャッシュ戦略では、効率的なデータ管理を解説していますが、OpenTelemetryのサンプリングもデータ効率化の重要な施策です。
Kubernetesでの運用を学ぶには、専門書籍Kubernetesの教科書 (Compass Booksシリーズ)を参考にすることで、OpenTelemetryのスケーラブルな配置戦略を理解できます。
コスト最適化:データ保持期間とフィルタリング
トレースデータの保持コストを削減するため、本番環境では7日、開発環境では1日など、環境に応じて保持期間を調整します。不要な属性を削除してデータサイズを削減し、ヘルスチェックなど不要なスパンを記録しないようにします。
実装では、OpenTelemetry Collectorのprocessorで、これらのフィルタリングを一元管理します。
アラート設定とインシデント対応
OpenTelemetryから生成されるメトリクスを基に、Prometheusアラートルールを設定することで、問題を早期に検知できます。重要なアラートルールには、p95レイテンシが閾値を超えた場合、エラー率が1%を超えた場合、リクエスト数が急激に低下した場合が含まれます。
トラブルシューティングと実装時の注意点
よくある実装ミスと対策
OpenTelemetry導入時に、トレースコンテキストの伝播忘れ(サービス間通信時にトレースIDを引き継がないとトレースが分断される)、過度な属性追加(トレースに大量の属性を追加するとデータサイズが増加)、Collectorの単一障害点化(複数インスタンスでの冗長化が必須)といったミスが頻繁に発生します。
パフォーマンスへの影響と最適化
OpenTelemetryの導入により、アプリケーションのパフォーマンスに若干の影響が生じます。一般的には、レイテンシが1~5%増加します。
最適化方法には、Collectorへのデータ送信をバッチ化してネットワークオーバーヘッドを削減、トレース記録を非同期で実行してメインロジックをブロックしない、本番環境では低いサンプリングレートを設定してオーバーヘッドを最小化することが含まれます。
セキュリティ考慮事項
トレースデータには、ユーザーIDやAPIキーなどの機密情報が含まれる可能性があります。機密情報を含む属性を自動的にマスク、Jaeger UIへのアクセスを認証・認可で制限、Collector~バックエンド間の通信をTLSで暗号化することが必要です。
Dockerコンテナセキュリティでは、多層防御体制を解説していますが、OpenTelemetry Collectorの冗長化とセキュリティ対策も可用性と機密情報保護の重要な施策です。
トラブルシューティングの実践的なノウハウを学ぶには、専門書籍チームトポロジーを参考にすることで、本番環境での運用ノウハウを体系的に理解できます。

まとめ
OpenTelemetryは、マイクロサービスアーキテクチャにおいて、分散トレーシングを通じてシステム全体の可視化を実現する必須のツールです。
本記事で解説した内容をまとめると:
- 基本概念:OpenTelemetryは、トレース・メトリクス・ログを統一的に収集するオープンスタンダード
- アーキテクチャ:Instrumentation→Collector→Exporter→バックエンド(Jaeger・Prometheus)の流れで実装
- 実装パターン:Python・Node.js・Goなど、主要言語で標準的なInstrumentationが提供されている
- 運用最適化:サンプリング戦略・コスト最適化・アラート設定により、本番環境での効率的な運用が可能
- 注意点:トレースコンテキストの伝播・パフォーマンス最適化・セキュリティ対策が重要
OpenTelemetryの導入により、問題特定時間の短縮、本番環境での信頼性向上、チーム間のコミュニケーション改善が実現できます。段階的な導入から始めて、組織全体でテレメトリ文化を醸成することが、長期的な成功の鍵となります。








