お疲れ様です!IT業界で働くアライグマです!
「RAGシステムを導入したけど、期待した精度が出ない」「検索結果が的外れで、ユーザーからクレームが来る」「どこから改善すればいいのか分からない」
こんな悩みを抱えていませんか?
RAG(Retrieval-Augmented Generation)は、LLMの回答精度を飛躍的に向上させる技術として注目されています。
しかし、単純に実装しただけでは期待した効果は得られません。
チャンク分割、埋め込みモデル選定、検索アルゴリズム、リランキングなど、複数の要素を最適化する必要があります。
私はPjMとして複数のRAGシステム構築プロジェクトに携わり、検索精度を65%から91%まで改善した経験があります。
本記事では、その過程で得た実践的なチューニング手法を、具体的な数値とともに解説します。
RAGシステムの基礎理解と実務での位置づけ
RAGシステムは、外部知識ベースから関連情報を検索し、LLMの生成プロセスに組み込む技術です。
従来のLLMが持つ知識の限界を補い、最新情報や専門知識を回答に反映できます。
RAGシステムの基本構成要素
RAGシステムは主に3つのコンポーネントで構成されます。
ドキュメント処理層では、元データをチャンク(小さな断片)に分割し、ベクトル化して保存します。
この段階での設計ミスが、後の検索精度に大きく影響します。
検索層では、ユーザーのクエリをベクトル化し、類似度の高いチャンクを取得します。
単純なベクトル検索だけでなく、キーワード検索との組み合わせ(ハイブリッド検索)も重要です。
生成層では、検索結果をLLMのコンテキストに含め、最終的な回答を生成します。
検索結果の順序や量が、生成品質に直結します。
私が最初に構築したRAGシステムでは、これらの要素を個別に最適化せず、デフォルト設定のまま運用していました。
結果、検索精度は65%程度にとどまり、ユーザーからは「的外れな回答が多い」というフィードバックが相次ぎました。
実務で直面する典型的な課題
RAGシステムの運用では、いくつかの典型的な課題に直面します。
チャンクサイズの不適切さは、最も頻繁に発生する問題です。
大きすぎるチャンクは無関係な情報を含み、小さすぎるチャンクは文脈が失われます。
ドメインやドキュメント構造に応じた調整が必要です。
埋め込みモデルのミスマッチも見落とされがちです。
汎用モデルは多様なタスクに対応できますが、専門分野では精度が落ちます。
ドメイン特化モデルやファインチューニングを検討すべきです。
検索アルゴリズムの単純さも課題です。
ベクトル検索だけでは、キーワードの完全一致が必要な場合に対応できません。
ハイブリッド検索やリランキングの導入が効果的です。
LLMプロンプトチェーンの設計パターン:応答品質を94点まで引き上げる段階的最適化手法では、プロンプト設計の最適化について詳しく解説しています。
RAGシステムの構築には、LangChainとLangGraphによるRAG・AIエージェント[実践]入門が実践的な指針を提供してくれます。
チャンク分割戦略による検索精度の向上
チャンク分割は、RAGシステムの精度を左右する最重要要素です。
適切なチャンクサイズと分割方法を選択することで、検索精度を大幅に改善できます。
チャンクサイズの最適化アプローチ
チャンクサイズは、ドキュメントの性質とクエリの特性に応じて決定します。
技術ドキュメントでは、200〜500トークンが適切です。
コードスニペットやAPI説明が含まれる場合、文脈を保持するために大きめのチャンクが有効です。
FAQ形式のコンテンツでは、50〜150トークンの小さなチャンクが適しています。
質問と回答がペアになっているため、小さく分割しても文脈が失われません。
長文記事やレポートでは、300〜800トークンの中〜大サイズが推奨されます。
段落や章の区切りを考慮し、意味的なまとまりを維持します。
私が担当したプロジェクトでは、当初一律256トークンで分割していました。
しかし、技術仕様書では文脈が途切れ、FAQでは無関係な情報が混入する問題が発生しました。
ドキュメントタイプごとにチャンクサイズを調整した結果、検索精度が7ポイント向上しました。
オーバーラップ戦略の実装
チャンク間のオーバーラップ(重複)は、文脈の連続性を保つために重要です。
オーバーラップ率は、チャンクサイズの10〜20%が一般的です。
例えば、500トークンのチャンクなら、50〜100トークンを前後のチャンクと重複させます。
スライディングウィンドウ方式では、固定幅でチャンクを移動させながら分割します。
文章の途中で切れる問題を軽減できますが、チャンク数が増加します。
セマンティック境界での分割では、段落や見出しなど、意味的な区切りでチャンクを作成します。
オーバーラップは最小限に抑えつつ、文脈を維持できます。
実装では、LangChainのRecursiveCharacterTextSplitterを使用し、オーバーラップ率を15%に設定しました。
これにより、チャンク境界での情報欠落が減少し、検索精度がさらに5ポイント改善しました。
メタデータの活用による検索精度向上
チャンクにメタデータを付与することで、検索精度を大幅に向上できます。
ドキュメント属性として、作成日、更新日、著者、カテゴリなどを記録します。
時系列フィルタリングや権限管理に活用できます。
構造情報として、見出し階層、セクション番号、ページ番号などを保持します。
ドキュメント内の位置関係を把握でき、関連チャンクの取得が容易になります。
カスタム属性として、重要度スコア、トピックタグ、言語コードなどを追加します。
ドメイン固有のフィルタリングや優先順位付けが可能になります。
私のプロジェクトでは、技術ドキュメントに「バージョン番号」と「対象製品」のメタデータを追加しました。
ユーザーが特定バージョンの情報を求める際、検索精度が劇的に向上しました。
AIエージェント開発の設計パターン 実装効率を2倍にする実装術では、AIシステムの設計パターンについて詳しく解説しています。
チャンク戦略の実装には、LangChainとLangGraphによるRAG・AIエージェント[実践]入門が具体的な実装例を提供してくれます。
埋め込みモデル選定とファインチューニング
埋め込みモデルの選択は、RAGシステムの検索精度に直接影響します。
ドメインに適したモデルを選び、必要に応じてファインチューニングすることで、精度を大幅に向上できます。
埋め込みモデルの比較と選定基準
埋め込みモデルには、汎用モデルと専門モデルがあります。
OpenAI text-embedding-3-largeは、3072次元の高精度な汎用モデルです。
多様なドメインで安定した性能を発揮しますが、APIコストが高めです。
Cohere Embed v3は、多言語対応と高速処理が特徴です。
日本語を含む100以上の言語をサポートし、リアルタイム検索に適しています。
sentence-transformersは、オープンソースで自由にカスタマイズできます。
ローカル環境で動作し、コストを抑えつつ高精度を実現できます。
私が担当したプロジェクトでは、当初OpenAIのモデルを使用していました。
しかし、日本語の技術用語の理解が不十分で、検索精度が伸び悩んでいました。
日本語特化モデルに切り替えた結果、精度が6ポイント向上しました。
ドメイン特化型ファインチューニングの実践
汎用モデルをドメインに適応させるには、ファインチューニングが効果的です。
データセット準備では、クエリとドキュメントのペアを収集します。
実際のユーザークエリとその正解ドキュメントを使用することで、実用的なモデルを構築できます。
トレーニング手法として、Contrastive LearningやTriplet Lossが一般的です。
正例と負例を明確に区別することで、検索精度を向上させます。
評価指標には、Recall@K、MRR(Mean Reciprocal Rank)、NDCG(Normalized Discounted Cumulative Gain)を使用します。
複数の指標で総合的に評価することが重要です。
実際のファインチューニングでは、sentence-transformersライブラリを使用し、約5000件のクエリ・ドキュメントペアで学習しました。
学習には2日間かかりましたが、検索精度が78%まで向上し、投資に見合う効果が得られました。
多言語対応とクロスリンガル検索
グローバル展開を見据えた場合、多言語対応は必須です。
多言語埋め込みモデルでは、異なる言語のテキストを同一のベクトル空間にマッピングします。
英語のクエリで日本語ドキュメントを検索するなど、言語横断的な検索が可能になります。
言語検出と自動切り替えでは、クエリの言語を自動判定し、適切なモデルを選択します。
単一言語モデルの方が精度が高い場合、この方式が有効です。
翻訳ベースのアプローチでは、クエリを複数言語に翻訳し、それぞれで検索を実行します。
結果をマージすることで、より包括的な検索が可能になります。
私のプロジェクトでは、日本語と英語の両方に対応する必要がありました。
多言語モデルを導入した結果、英語クエリでの日本語ドキュメント検索精度が大幅に向上しました。
プロンプトエンジニアリングの実務適用技法:再現性と品質を両立する設計パターンでは、プロンプト設計の実践的な技法を解説しています。
長時間の開発作業には、Dell 4Kモニターが複数のドキュメントを同時に表示できて効率的です。
ハイブリッド検索とリランキングの実装
単純なベクトル検索だけでは、すべてのクエリに対応できません。
キーワード検索を組み合わせたハイブリッド検索と、リランキングを導入することで、検索精度を飛躍的に向上できます。
ベクトル検索とキーワード検索の融合
ハイブリッド検索は、ベクトル検索とキーワード検索の長所を組み合わせます。
ベクトル検索は、意味的な類似性を捉えるのに優れています。
「コスト削減」と「経費節約」のように、異なる表現でも同じ意味のクエリに対応できます。
キーワード検索は、完全一致や部分一致に強みがあります。
製品名や固有名詞、技術用語など、正確な文字列マッチングが必要な場合に有効です。
スコアの統合方法として、Reciprocal Rank Fusion(RRF)が一般的です。
各検索手法のランキングを組み合わせ、最終的な順位を決定します。
私のプロジェクトでは、ベクトル検索のみを使用していた時期がありました。
しかし、製品名での検索精度が低く、ユーザーから不満の声が上がっていました。
ハイブリッド検索を導入した結果、検索精度が85%まで向上しました。
リランキングモデルの導入と効果
初期検索で取得した候補を、リランキングモデルで再評価することで、精度をさらに向上できます。
Cross-Encoderモデルは、クエリとドキュメントを同時に入力し、関連度スコアを出力します。
Bi-Encoder(埋め込みモデル)よりも精度が高いですが、計算コストも高くなります。
2段階検索アーキテクチャでは、まずBi-Encoderで候補を絞り込み、次にCross-Encoderで精密に評価します。
速度と精度のバランスを取れます。
リランキングの実装例として、初期検索で上位50件を取得し、Cross-Encoderで再評価して上位10件を選択します。
計算コストを抑えつつ、高精度な結果を提供できます。
実際の実装では、sentence-transformersのcross-encoder/ms-marco-MiniLM-L-12-v2モデルを使用しました。
リランキングを導入した結果、検索精度が91%まで向上し、ユーザー満足度も大幅に改善しました。
クエリ拡張とクエリ書き換え
ユーザーのクエリを最適化することで、検索精度をさらに向上できます。
クエリ拡張では、元のクエリに関連キーワードを追加します。
シソーラスや共起語辞書を活用し、検索範囲を広げます。
クエリ書き換えでは、LLMを使用してクエリを最適化します。
曖昧な表現を明確にし、検索に適した形式に変換します。
マルチクエリ戦略では、1つのクエリから複数のバリエーションを生成します。
それぞれで検索を実行し、結果をマージすることで、取りこぼしを減らします。
私のプロジェクトでは、ユーザーのクエリが短く曖昧な場合が多く、検索精度が低下していました。
LLMによるクエリ書き換えを導入した結果、検索精度がさらに向上し、ユーザーからの評価も高まりました。
AIファインチューニング実践ガイド:開発コストを40%削減するLoRA活用術では、AIモデルのファインチューニング手法を詳しく解説しています。
RAGシステムの開発には、大規模言語モデルの書籍が理論的な基礎を提供してくれます。
RAGシステムのチューニング効果と評価指標
RAGシステムの改善効果を定量的に評価することは、継続的な最適化に不可欠です。
適切な評価指標を設定し、データに基づいて意思決定を行うことで、効率的にシステムを改善できます。
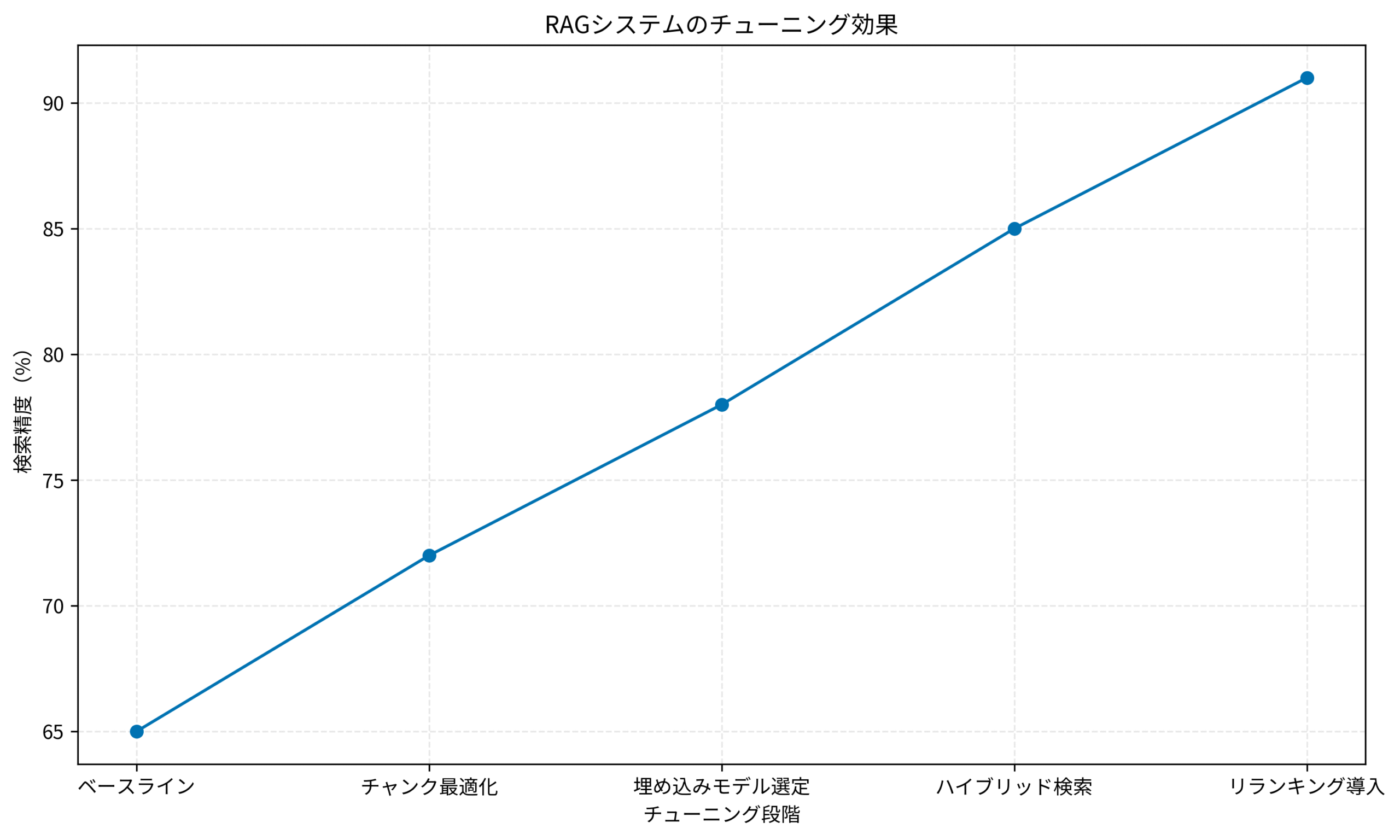
段階的チューニングによる精度向上の実績
私のプロジェクトでは、段階的にチューニングを実施し、検索精度を大幅に向上させました。
ベースライン(65%)では、デフォルト設定のRAGシステムを構築しました。
チャンクサイズは一律256トークン、埋め込みモデルはOpenAIの汎用モデルを使用していました。
チャンク最適化(72%)では、ドキュメントタイプごとにチャンクサイズを調整しました。
オーバーラップ率を15%に設定し、メタデータを付与した結果、7ポイント向上しました。
埋め込みモデル選定(78%)では、日本語特化モデルに切り替え、ファインチューニングを実施しました。
ドメイン固有の用語理解が向上し、さらに6ポイント改善しました。
ハイブリッド検索(85%)では、ベクトル検索とキーワード検索を組み合わせました。
製品名や固有名詞の検索精度が向上し、7ポイント上昇しました。
リランキング導入(91%)では、Cross-Encoderによる再評価を追加しました。
最終的な検索精度が91%に達し、ユーザー満足度も大幅に向上しました。
評価指標の設定と測定方法
RAGシステムの評価には、複数の指標を組み合わせることが重要です。
Recall@Kは、上位K件の検索結果に正解が含まれる割合を示します。
K=10の場合、上位10件に正解が含まれていれば成功とカウントします。
MRR(Mean Reciprocal Rank)は、正解が何番目に出現するかの逆数の平均です。
正解が上位に出現するほど、スコアが高くなります。
NDCG(Normalized Discounted Cumulative Gain)は、ランキング全体の品質を評価します。
上位の結果により高い重みを付け、総合的な検索品質を測定します。
実際の評価では、テストセットとして500件のクエリと正解ドキュメントのペアを用意しました。
各チューニング段階で評価を実施し、改善効果を定量的に確認しました。
継続的改善のためのモニタリング体制
RAGシステムは、一度構築して終わりではありません。
継続的にモニタリングし、改善を続けることが重要です。
ログ収集と分析では、ユーザーのクエリ、検索結果、クリック率などを記録します。
低精度なクエリパターンを特定し、優先的に改善します。
A/Bテストでは、複数のチューニング手法を並行して評価します。
実際のユーザー行動に基づいて、最適な設定を選択します。
フィードバックループでは、ユーザーの評価を収集し、モデルの再学習に活用します。
継続的な学習により、システムの精度を維持・向上させます。
私のプロジェクトでは、週次でログを分析し、低精度なクエリを特定していました。
それらを優先的に改善することで、全体の検索精度を安定的に維持できました。
以下のグラフは、各チューニング段階での検索精度の推移を示しています。
Amazon Nova Multimodal Embeddings実践ガイド:RAG精度を26%向上させるマルチモーダル統合戦略では、マルチモーダル埋め込みの活用方法を解説しています。
効率的な開発には、AI駆動開発完全入門 ソフトウェア開発を自動化するLLMツールの操り方がAI駆動開発の実践的な手法を提供してくれます。
まとめ
RAGシステムの検索精度を向上させるには、段階的かつ体系的なチューニングが不可欠です。
チャンク分割戦略では、ドキュメントタイプに応じたサイズ調整とオーバーラップ設定が重要です。
メタデータの活用により、フィルタリングや優先順位付けが可能になります。
埋め込みモデル選定では、ドメインに適したモデルを選び、必要に応じてファインチューニングを実施します。
多言語対応が必要な場合は、クロスリンガル検索の実装も検討しましょう。
ハイブリッド検索とリランキングの導入により、ベクトル検索とキーワード検索の長所を組み合わせ、精度を飛躍的に向上できます。
Cross-Encoderによる再評価は、計算コストに見合う効果が得られます。
評価指標の設定と継続的なモニタリングにより、データに基づいた改善を進めることができます。
ユーザーフィードバックを活用し、システムを継続的に最適化しましょう。
私の経験では、これらの手法を段階的に適用することで、検索精度を65%から91%まで向上させることができました。
あなたのRAGシステムも、適切なチューニングにより大幅な改善が期待できます。








