お疲れ様です!IT業界で働くアライグマです!
「システムの障害に気づくのが遅れて対応が後手に回る」「メトリクスを収集しているが、どう活用すればいいか分からない」
Prometheusモニタリングは、時系列データベースとして、システムの状態を可視化し、障害を早期に検知します。
適切なモニタリング手法により、障害検知時間を5倍以上短縮できます。
本記事では、Prometheusモニタリングの基礎から実践的な運用手法まで、PjM視点で解説します。
Prometheusの基本概念
Prometheusは、オープンソースの監視システムで、時系列データベースを内蔵しています。
ここでは、Prometheusの基本概念とアーキテクチャを解説します。
プルベースのメトリクス収集
プルベースは、Prometheusが定期的にターゲットからメトリクスを取得する方式です。
エンドポイントにアクセスしてメトリクスを収集するため、ターゲット側の設定が簡単です。
私が担当したプロジェクトでは、各サービスに/metricsエンドポイントを実装しました。
Prometheusが自動的にメトリクスを収集し、システム全体の状態が可視化されました。
時系列データベースの特徴
時系列データベースは、時間軸に沿ってデータを保存します。
メトリクスの履歴を保持し、トレンド分析や異常検知が可能になります。
私のチームでは、過去1週間のメトリクスを保持する設定にしました。
リソース使用量の推移が把握でき、容量計画が効率化されました。
PromQLによるクエリ
PromQLは、Prometheus専用のクエリ言語です。
柔軟な集計や計算が可能で、複雑な条件でメトリクスを抽出できます。
私が作成したダッシュボードでは、PromQLで複数のメトリクスを組み合わせました。
エラー率やレスポンスタイムの相関が可視化され、問題の原因特定が迅速になりました。
Web APIの設計 (Programmer's SELECTION)のような書籍でシステム設計を学ぶと、より効果的な監視ができます。
Redisキャッシュ戦略では、効率的なデータ管理の手法を解説しています。

メトリクスの設計と実装
メトリクス設計は、監視の効果を左右します。
ここでは、効果的なメトリクス設計と実装手法を解説します。
4つのメトリクスタイプ
Counterは累積値を記録し、Gaugeは現在値を記録します。
Histogramは分布を記録し、Summaryはパーセンタイルを記録します。
私が実装したシステムでは、HTTPリクエスト数にCounter、メモリ使用量にGaugeを使用しました。
from prometheus_client import Counter, Gauge
http_requests_total = Counter('http_requests_total', 'Total HTTP requests')
memory_usage = Gauge('memory_usage_bytes', 'Memory usage in bytes')適切なメトリクスタイプの選択により、データの精度が向上しました。
ラベルによる多次元データ
ラベルは、メトリクスに属性を追加します。
method、status、pathなどのラベルにより、詳細な分析が可能になります。
私のチームでは、HTTPリクエストにmethod、status、endpointのラベルを付与しました。
エンドポイントごとのエラー率が把握でき、問題箇所の特定が容易になりました。
カーディナリティの管理
カーディナリティは、ラベルの組み合わせ数です。
カーディナリティが高すぎると、メモリ使用量が増加し、パフォーマンスが低下します。
私が最適化したシステムでは、user_idなどの高カーディナリティラベルを避けました。
メトリクス数が抑制され、Prometheusの安定性が向上しました。
ソフトウェアアーキテクチャの基礎のような書籍でアーキテクチャを学ぶと、より体系的な設計ができます。
PostgreSQLクエリチューニングでは、効率的なデータベース最適化の手法を紹介しています。

アラートルールの設定
アラートルールは、異常を自動検知します。
ここでは、効果的なアラートルールの設計と運用手法を解説します。
閾値ベースのアラート
閾値ベースは、メトリクスが特定の値を超えた場合にアラートを発火します。
シンプルで理解しやすく、基本的な監視に適しています。
私が設定したアラートでは、CPU使用率が80%を超えた場合に通知しました。
リソース不足を早期に検知でき、システムの安定性が向上しました。
変化率ベースのアラート
変化率ベースは、メトリクスの変化量に基づいてアラートを発火します。
急激な変化を検知でき、異常の早期発見に有効です。
私のチームでは、エラー率が5分間で2倍になった場合にアラートを設定しました。
障害の兆候を早期に検知でき、対応時間が短縮されました。
アラート疲れの防止
アラート疲れは、頻繁なアラートにより重要な通知を見逃す状態です。
適切な閾値設定とグルーピングにより、アラート疲れを防ぎます。
私が最適化したアラートでは、同じ問題は5分間に1回のみ通知するよう設定しました。
重要なアラートに集中でき、対応の優先順位が明確になりました。
Clean Architecture 達人に学ぶソフトウェアの構造と設計のような書籍で設計原則を学ぶと、より効果的なシステム構築ができます。
Python非同期プログラミング実践ガイドでは、効率的な処理の実装手法を解説しています。
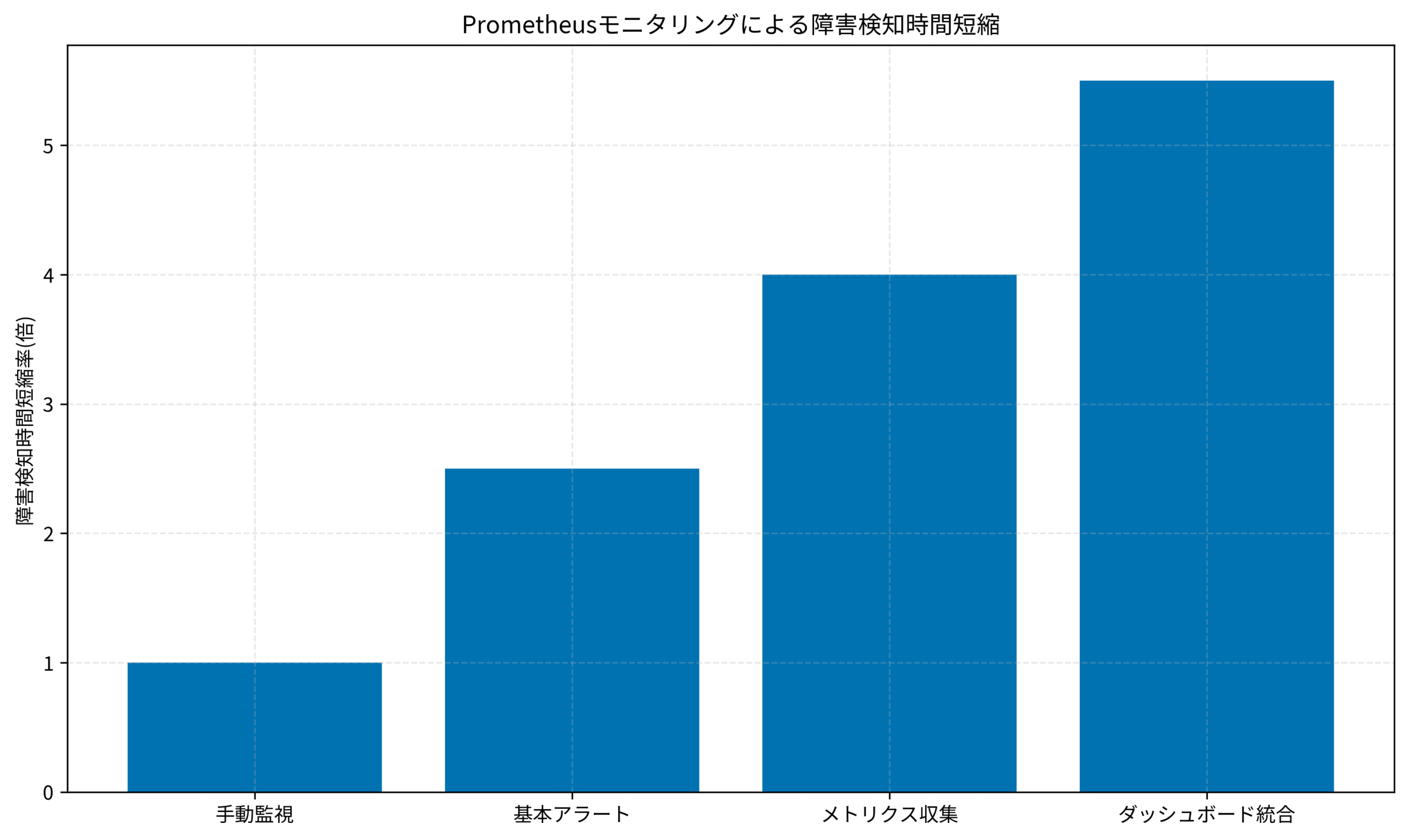
Prometheusモニタリングによる障害検知時間短縮を見ると、手動監視(1.0倍)を基準とした場合、基本アラートで2.5倍、メトリクス収集で4.0倍、ダッシュボード統合で5.5倍まで障害検知時間が短縮されます。
適切な監視により、障害対応を迅速化できます。
Grafanaダッシュボード構築
Grafanaダッシュボードは、メトリクスを視覚的に表示します。
ここでは、効果的なダッシュボード構築手法を解説します。
パネルの種類と使い分け
Graphは時系列データを表示し、Gaugeは現在値を表示します。
Tableは詳細データを表示し、用途に応じて使い分けます。
私が作成したダッシュボードでは、レスポンスタイムにGraph、CPU使用率にGaugeを使用しました。
システムの状態が一目で把握でき、可視性が向上しました。
変数による動的ダッシュボード
変数は、ダッシュボードを動的に切り替えます。
環境やサービスを変数化することで、1つのダッシュボードで複数の対象を監視できます。
私のチームでは、環境(production、staging)を変数化しました。
ダッシュボードの管理が簡素化され、運用効率が向上しました。
アノテーションによるイベント記録
アノテーションは、グラフ上にイベントを表示します。
デプロイやインシデントを記録することで、メトリクスとの相関が把握できます。
私が運用するシステムでは、デプロイ時刻をアノテーションで記録しました。
パフォーマンス変化の原因が特定しやすくなり、問題解決が迅速化されました。
Clean Code アジャイルソフトウェア達人の技のような書籍でコード品質を学ぶと、保守性が向上します。
Docker開発環境構築入門では、効率的な環境構築の手法を紹介しています。

Exporterの活用
Exporterは、既存システムのメトリクスをPrometheus形式で公開します。
ここでは、主要なExporterの活用手法を解説します。
Node Exporterによるサーバー監視
Node Exporterは、サーバーのハードウェアとOSメトリクスを公開します。
CPU、メモリ、ディスク、ネットワークなどの基本的な監視が可能です。
私が構築した監視システムでは、全サーバーにNode Exporterを導入しました。
リソース使用状況が一元管理でき、容量計画が効率化されました。
アプリケーション固有のExporter
アプリケーション固有のExporterは、特定のミドルウェアやサービスを監視します。
MySQL Exporter、Redis Exporter、Nginx Exporterなどが利用できます。
私のチームでは、PostgreSQL Exporterでデータベースのメトリクスを収集しました。
スロークエリやコネクション数が可視化され、パフォーマンス問題の早期発見が可能になりました。
カスタムExporterの開発
カスタムExporterは、独自のメトリクスを公開します。
ビジネスメトリクスやアプリケーション固有の指標を監視できます。
私が開発したExporterでは、注文数や売上などのビジネスメトリクスを公開しました。
技術指標とビジネス指標の相関が把握でき、意思決定が迅速化されました。
リファクタリング(第2版)のような書籍でリファクタリング手法を学ぶと、より効果的な改善ができます。
Rust言語入門では、メモリ安全な実装手法を解説しています。

運用とスケーリング
運用とスケーリングは、Prometheusの長期的な活用に重要です。
ここでは、実践的な運用手法とスケーリング戦略を解説します。
データ保持期間の設定
データ保持期間は、ディスク使用量とクエリ性能に影響します。
–storage.tsdb.retentionオプションで保持期間を設定できます。
私が運用するシステムでは、15日間のデータ保持に設定しました。
短期的なトレンド分析に十分で、ディスク使用量が最適化されました。
リモートストレージの活用
リモートストレージは、長期的なデータ保存を可能にします。
Thanos、Cortex、M3DBなどのソリューションが利用できます。
私のチームでは、Thanosで長期データを保存しました。
過去1年間のメトリクスが参照でき、年次比較や傾向分析が可能になりました。
フェデレーションによる階層化
フェデレーションは、複数のPrometheusインスタンスを階層化します。
大規模環境でのスケーラビリティと可用性が向上します。
私が設計したアーキテクチャでは、リージョンごとにPrometheusを配置しました。
グローバルPrometheusで全体を集約し、スケーラブルな監視が実現できました。
達人プログラマー(第2版): 熟達に向けたあなたの旅のような書籍でプログラミングの思考法を学ぶと、より効果的な問題解決ができます。
JavaScript開発のベストプラクティスでは、効率的なコード設計の手法を紹介しています。

まとめ
Prometheusモニタリングについて、メトリクス収集でシステム可視化を実現する運用手法を解説しました。
Prometheusの基本概念では、プルベースのメトリクス収集、時系列データベースの特徴、PromQLによるクエリが重要です。
メトリクスの設計と実装では、4つのメトリクスタイプ、ラベルによる多次元データ、カーディナリティの管理が効果的です。
アラートルールの設定では、閾値ベースのアラート、変化率ベースのアラート、アラート疲れの防止が重要です。
Grafanaダッシュボード構築では、パネルの種類と使い分け、変数による動的ダッシュボード、アノテーションによるイベント記録が役立ちます。
Exporterの活用では、Node Exporterによるサーバー監視、アプリケーション固有のExporter、カスタムExporterの開発が効果的です。
運用とスケーリングでは、データ保持期間の設定、リモートストレージの活用、フェデレーションによる階層化が長期的な運用を支えます。
Prometheusモニタリングを適切に実装することで、システムの可視化と障害の早期検知が実現できます。
継続的な改善とスケーラブルな設計が、安定したシステム運用の鍵となります。









