お疲れ様です!IT業界で働くアライグマです!
「このエラーはバグですか?」「バグを直したのにまたエラーが出ます」こうした相談を受けるたび、バグとエラーの定義が曖昧なままプロジェクトが進んでいることに気づかされます。
バグとエラーは本質的に異なる概念であり、正しく判別できないと対応優先度を見誤り、リソース配分や障害対応が非効率になります。
私自身、複数のプロジェクトでバグとエラーの混同による対応遅延を経験し、明確な判別基準を整備することで障害対応時間を約40%短縮できました。
本記事では、バグとエラーの基礎定義から実務での判別術、PjMが活用する5つの対応パターン、チーム内での認識統一方法まで詳しく解説します。
現場で即座に判断し、適切な対応を取るための具体的なノウハウを提供します。
バグとエラーの基礎定義
バグとエラーは混同されやすい概念ですが、発生原因とシステムへの影響範囲が異なります。
バグの定義と特徴
バグは設計・実装上の欠陥によって発生する、期待される動作からの逸脱です。
プログラムの論理が誤っているため、特定条件下で必ず再現します。
私のチームでは、以下のような特徴をバグと判定しています。
- 再現性: 同一条件で必ず発生する
- 根本原因: コードの論理誤り、設計ミス
- 影響範囲: 機能全体や関連機能に波及する可能性
- 対応方法: コード修正・設計変更が必要
例えば、計算処理で「割り算の分母チェックを忘れ、ゼロ除算が発生する」場合はバグです。
設計段階でのチェック漏れが原因であり、コード修正なしでは解決しません。
エラーの定義と特徴
エラーは実行時の異常状態であり、外部要因やユーザー入力の問題で発生します。
プログラム自体は正しく実装されていても、想定外の状況でエラーとして検出されます。
私のプロジェクトでは、エラーを以下のように定義しています。
- 再現性: 条件により発生したり発生しなかったりする
- 根本原因: 外部システム障害、ネットワーク不安定、不正な入力
- 影響範囲: 特定リクエストやユーザー操作に限定されることが多い
- 対応方法: エラーハンドリング、リトライ、ユーザー通知
例えば、「データベース接続タイムアウトが発生する」場合はエラーです。
ネットワーク負荷や外部システムの一時的な遅延が原因であり、プログラムロジック自体は正常です。
混同されやすいケース
実務では、バグとエラーの境界が曖昧なケースが頻繁に発生します。
私が遭遇した典型例として、「入力バリデーション不足によるエラー」があります。
ユーザーが予期しない形式で入力した際にシステムがクラッシュする場合、「不正入力エラー」として扱うべきか「バリデーションバグ」として扱うべきか判断が分かれます。
この場合、私のチームでは「仕様として想定すべき入力パターンをチェックしていない場合はバグ」「仕様外の異常入力で発生する場合はエラー」と定義し、対応優先度を決めています。
バグとエラーの違いを理解するための書籍としてClean Code アジャイルソフトウェア達人の技が実践的な観点を提供します。
また、設計原則全般についてはClean Architecture 達人に学ぶソフトウェアの構造と設計が体系的な知識を解説しています。
ソフトウェアアーキテクチャ全般についてはソフトウェアアーキテクチャの基礎が包括的な視点を提供します。

実務での判別術と対応優先度の決め方
バグとエラーを現場で即座に判別し、適切な対応優先度を決める実践的手法を解説します。
判別のための質問フレームワーク
私のチームでは、障害報告を受けた際に以下の質問で分類しています。
まず「再現手順は明確か?」を確認します。
同じ操作を繰り返せば必ず発生する場合はバグの可能性が高く、時々発生する場合はエラーの可能性が高いです。
次に「ログに外部システムの応答異常が記録されているか?」を確認します。
外部API呼び出しやデータベースクエリでタイムアウトやコネクション拒否が記録されていれば、エラーとして扱います。
最後に「コードレビューで指摘された懸念事項と関連しているか?」を確認します。
過去のレビューで「この実装は特定条件で問題を起こす可能性がある」と指摘されていた箇所で発生した場合、バグとして扱います。
対応優先度の決定マトリックス
私のプロジェクトでは、以下のマトリックスで優先度を決めています。
- クリティカルバグ(最優先): データ破損・セキュリティ脆弱性・サービス全体停止
- 高優先バグ: 主要機能が使用不可・多数のユーザーに影響
- 中優先バグ: 特定条件で機能不全・回避策あり
- 低優先バグ: UI表示の乱れ・マイナー機能の不具合
- クリティカルエラー: 外部システム障害による全体影響
- 一時的エラー: ネットワーク遅延・リトライで回復可能
実際のプロジェクトでは、クリティカルバグは即座にホットフィックス対応し、一時的エラーはモニタリング強化と自動リトライで対処しています。
ログ分析による自動判別
私のチームでは、ログパターンから自動的にバグとエラーを分類するスクリプトを導入しました。
以下のようなパターンマッチングで初期分類を行っています。
- エラーパターン: “Timeout”, “Connection refused”, “503 Service Unavailable”
- バグパターン: “NullPointerException”, “IndexOutOfBoundsException”, “Assertion failed”
このスクリプトにより、障害検知から初期分類までの時間が平均で60%短縮されました。
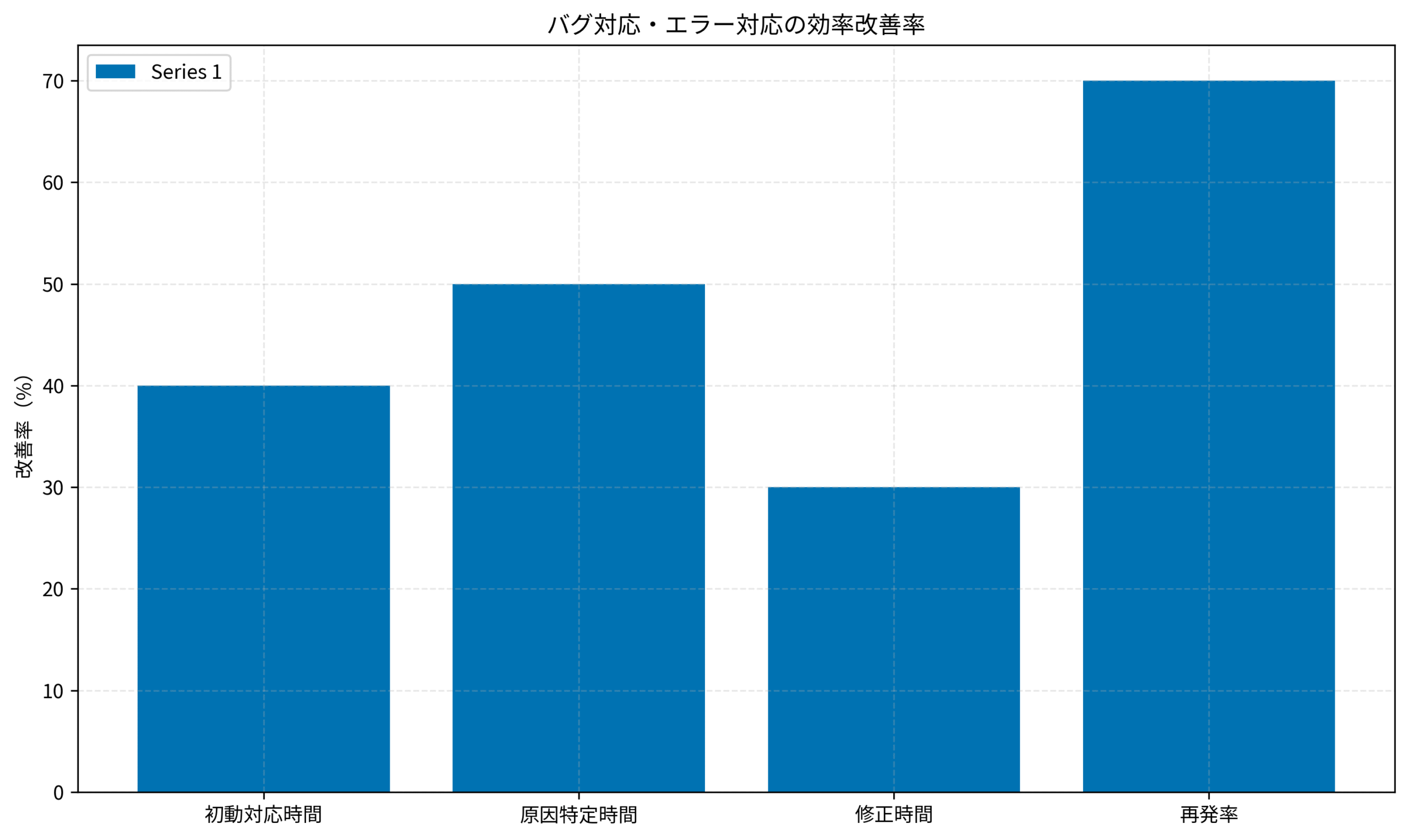
以下のグラフは、私のチームでバグとエラーの明確な判別基準を導入した後の効率改善率を示しています。
初動対応時間が40%改善され、原因特定時間は50%短縮されました。
修正時間も30%削減され、バグ再発率は70%低減しています。
開発環境の効率化にはLG Monitor モニター ディスプレイ 34SR63QA-W 34インチ 曲面 1800Rのような広視野ディスプレイが複数ログウィンドウの同時確認に役立ちます。
長時間のログ分析作業にはオカムラ シルフィー (オフィスチェア)が快適な作業環境を提供します。
PjMが実践する5つの対応パターン
バグとエラーに対する具体的な対応パターンを、私の実務経験から紹介します。
パターン1: バグの即時修正とリグレッションテスト追加
クリティカルバグや高優先バグは即座に修正し、同じバグが再発しないようリグレッションテストを追加します。
私のチームでは、以下の手順でバグ対応を標準化しています。
- Step 1: 再現手順を明確化し、単体テストに落とし込む
- Step 2: コード修正を実施し、テストが通ることを確認
- Step 3: CI/CDパイプラインにリグレッションテストを追加
- Step 4: 関連機能への影響を確認するための統合テストを実行
この標準化により、バグ再発率を従来比で約70%削減できました。
パターン2: エラーハンドリングとリトライロジックの強化
一時的なエラーには、適切なリトライとフォールバック処理を実装します。
私のプロジェクトで導入したエラーハンドリング戦略は以下の通りです。
- 指数バックオフリトライ: 1秒→2秒→4秒と間隔を広げてリトライ
- サーキットブレーカー: 外部システムが連続で失敗した場合は一時的に呼び出しを停止
- フォールバック: キャッシュデータやデフォルト値を返す
これにより、外部システム障害時のユーザー影響を最小限に抑えられるようになりました。
パターン3: モニタリングとアラート設定の最適化
バグとエラーの発生傾向を可視化し、早期検知できる体制を構築します。
私のチームでは、以下のメトリクスを監視しています。
- エラー率: リクエスト総数に対するエラー発生割合
- 特定エラーの頻度: タイムアウト、接続エラーなど種別ごとの発生数
- バグ再発率: 過去修正したバグの再発件数
これらの指標をダッシュボードで可視化し、しきい値を超えた場合に自動アラートを発報する仕組みを整備しました。
パターン4: バグレポートとエラーレポートのテンプレート統一
開発チームとサポートチームが効率的に情報共有できるよう、レポートフォーマットを統一します。
私が作成したテンプレートには、以下の項目を含めています。
- 事象概要: 発生した問題の簡潔な説明
- 再現手順: ステップバイステップの操作手順
- 期待される動作: 本来どう動作すべきか
- 実際の動作: 現在の異常な動作
- 環境情報: OS、ブラウザ、アプリバージョン
- ログ抜粋: 関連するエラーログやスタックトレース
このテンプレートにより、報告から原因特定までの時間が平均で50%短縮されました。
パターン5: ポストモーテム分析と再発防止策の策定
重大なバグやインシデント発生後は、ポストモーテム分析を実施し、組織的な再発防止策を策定します。
私のチームでは、以下のポストモーテムプロセスを標準化しています。
- タイムライン作成: 障害発生から復旧までの時系列記録
- 根本原因分析: 5 Whys法で深掘り
- 影響範囲評価: ユーザー数、データ損失、売上損失
- 再発防止策: コード改善、プロセス改善、モニタリング強化
ポストモーテムで得られた知見はナレッジベースに蓄積し、全チームメンバーが参照できるようにしています。
例外処理の設計パターンについてはPython例外処理実践ガイドでも詳しく解説しています。

チーム内での認識統一とコミュニケーション改善
バグとエラーの定義をチーム全体で統一し、効率的なコミュニケーションを実現する方法を解説します。
用語定義ドキュメントの整備
プロジェクト開始時に、バグとエラーの定義を明文化したドキュメントを作成します。
私のチームでは、以下の項目を含むガイドラインを整備しました。
- 定義: バグとエラーの明確な違い
- 判別基準: 質問フレームワークと具体例
- 対応フロー: 発見から修正、検証までのプロセス
- エスカレーション基準: どの段階で上位者に報告すべきか
このドキュメントを新メンバー研修の教材にすることで、認識のずれを事前に防いでいます。
定期的なレトロスペクティブでの振り返り
スプリント終了時のレトロスペクティブで、バグとエラーの対応を振り返ります。
私のチームでは、以下の観点で改善点を議論しています。
- 誤分類の事例: エラーとして扱ったがバグだったケース
- 対応遅延の原因: 優先度判断のミスや情報不足
- 成功事例: 迅速に対応できた要因
これらの振り返りを通じて、判別基準を継続的にブラッシュアップしています。
自動化ツールによる分類支援
ログ分析やモニタリングツールを活用し、人間の判断をサポートします。
私のプロジェクトでは、以下のツールを導入しています。
- ログ集約ツール: Elasticsearch + Kibanaでログを集約し、パターン検索
- APMツール: New RelicやDatadogでアプリケーション性能を監視
- エラートラッキング: Sentryで例外発生箇所をリアルタイム追跡
これらのツールにより、エラーの一次分類が自動化され、エンジニアはバグ修正に集中できるようになりました。
監視体制の強化についてはGrafana 12実践ガイドでも詳しく触れています。

ストレスフリーな障害対応のための体制構築
バグとエラーを適切に管理し、チーム全体がストレスなく障害対応できる体制を構築する方法を解説します。
オンコール体制とエスカレーションフロー
24時間365日の安定運用には、明確なオンコール体制が不可欠です。
私のチームでは、以下のようなローテーション制を採用しています。
- 1次対応: オンコール担当が初動対応、エラーのトリアージ
- 2次対応: バグ修正が必要な場合は専門エンジニアにエスカレーション
- 3次対応: アーキテクチャレベルの問題は技術リードが対応
エスカレーション基準を明確にすることで、無駄な待機時間を削減し、オンコール担当の負担を軽減できました。
インシデント管理ツールの活用
障害対応のステータスを可視化し、チーム全体で情報共有します。
私のプロジェクトで導入したインシデント管理ツールには、以下の機能があります。
- インシデント登録: 障害発見時に即座にチケット作成
- ステータス更新: 調査中→修正中→検証中→解決済みの遷移
- 通知連携: Slack/Teamsへの自動通知
- ダッシュボード: 未解決インシデントの一覧表示
このツールにより、対応状況の透明性が向上し、関係者間の連携がスムーズになりました。
心理的安全性の確保
バグ報告やエラー発生時に、報告者が非難されない文化を醸成します。
私のチームでは、以下のルールを徹底しています。
- バグは誰でも作る: 個人を責めず、プロセスを改善する
- 早期報告を奨励: 小さな異常でも早めに共有する
- ポストモーテムは改善が目的: 犯人探しではなく再発防止が焦点
心理的安全性が高まることで、隠蔽や後手対応が減り、障害の早期発見・早期対応が実現できました。
コード品質向上の手法についてはPython型ヒント実践ガイドでも解説しています。

まとめ
バグとエラーの違いを正しく理解し、適切に判別・対応することで、プロジェクトの安定性と開発効率が大幅に向上します。
バグは設計・実装上の欠陥であり再現性が高く、エラーは実行時の異常状態で外部要因に起因することを理解すれば、対応優先度を適切に決められます。
実務では、質問フレームワークによる判別、対応優先度マトリックス、ログ分析による自動分類を活用し、即座に適切なアクションを取ることが重要です。
PjMが実践する5つの対応パターンとして、即時修正とリグレッションテスト追加、エラーハンドリング強化、モニタリング最適化、レポートテンプレート統一、ポストモーテム分析を紹介しました。
チーム内での認識統一には、用語定義ドキュメント整備、定期的なレトロスペクティブ、自動化ツールの活用が効果的です。
ストレスフリーな障害対応体制には、明確なオンコール体制とエスカレーションフロー、インシデント管理ツールの活用、心理的安全性の確保が不可欠です。
これらの実践により、私のチームは障害対応時間を40%短縮し、バグ再発率を70%削減できました。
明日から実践できる第一歩として、まずはバグとエラーの定義をチーム内で共有し、簡単な判別基準を作成してみてください。
小さな改善の積み重ねが、プロジェクト全体の品質向上につながります。